码农的假期
又一个「劫日」
我历来对假期没有特别的概念。以前读书的时候,基本上是天天在图书馆泡着,要么是在发呆要么是在准备发呆的状态中。一方面是自己的借口,不大好动,喜欢宅,也不怎么喜欢出去游山玩水之类的,毕竟读书时候生活费总共就没几个子;另一方面,总是感觉有许多的东西要在假期这段时间好好弥补一下,刚好趁着假期有充分完整的时间可以利用。总而言之,以前自己特么像个书呆子。所以至今开始工作后,我也没觉得假期是多么一个「神圣不可剥夺」的权利。
家里老婆和孩子去顺德母校参加活动,家里只有留自己一个人在耗着。一边感慨厦门一到假期就人满为患,先前读书的时候也是因为假期学校被游客「占领」,食堂没个吃饭的位,溜圈没个歇脚的地,甚至有一段时间厦大的图书馆都开始警报说「有一大波僵尸在靠近」。印象中我曾经固执的认为假期就如同我的死期似的,整个人没法子活了。所以老婆一说我可以趁这个时间出去走走的想法时,我连忙表示「誓死反对」。也罢,以前读书时候留下的老毛病,那也就重拾书本,开始书呆子的「宅期」了。
码农在行动
突然想起放假前有同事给我下了个命令,要用 R 来写一个小小的程序,帮其减少体力活。我本来想说的是,我又不是个专业码农,干嘛有事没事非得都往这边推呢。不过,至少是半个码农的我,平日里最看不得那些愚蠢的、浪费大量时间和精力去做一个重复的体力活了。比如我这个同事,她需要每天统计部门推荐的股票,然后在收盘时间登记相应的收盘信息,计算每支股票的收益情况,并最终汇总。其实我一开始看到这个「又脏又累」的苦逼活时,表示了强烈的鄙视感与完全没有和谐美的道义谴责。这些活一来是高度重复、机械的,没有必要每天花那么多的时间去重复消耗时间;二来,其实可以在事前先花一点时间好好设计一套程序,让代码自动运行给给出想要的结果,而且还能保证不出差错(她每天都担心是不是计算结果有误,结果在 Excel 运行结束后又得使用计算器再次验证结果)。当时有跟她商量过是不是可以考虑使用代码来实现。可是她嫌麻烦,又怕事,也不懂编程,觉得没有必要。在说完她的 N 个理由后,我那仅存的一丁点的码农精神彻底无语。也就罢了,自己还有一堆的事情要去完成。
这几天正值假期空闲,又想起这件事情。手痒痒的,便自觉不自觉的拿起键盘,开始稀里哗啦的敲击。以下是事后的备忘录,以防这位同事日后问起程序的任何问题,我好歹还能把这篇博客拿出来。
基本思路
其实整个程序的思路应该是很明朗的:使用股票代码作为参数输入,经过函数转换,得到想要的结果。具体点,就是个股的收益率计算,比赛排名与得分,总体的平均收益率。另外最好能够添加个股的基本情况介绍,如主营业务,当日行情,累计收益率等。
输入参数
要求输入的参数越少越好,中间的格式转换全交给代码去处理。我想了一下,最简单的输入参数必须包括(姐们,实在不能再少了):
- 股票代码,如
600562 - 股票推荐价格。由于第一支股票是在开盘时间推荐,故而可以直接使用开盘价格作为推荐价。那么我们只需要输入第二支股票的价格即可。
一言以蔽之,就是形如以下格式的代码
FL <- c("600990", "300020", 29.3)
WW <- c("300168", "600562", 40)
LYJ <- c("002594", "000768", 16)
WXZ <- c("601766", "601818", 2.74)
YYY <- c("600967", "601002", 11.25)
其中,需要注意的是:由于深圳股市的股票有部分是从 00 开头的,这要求我们在输入股票代码的时候,不能以数值形式储存,不然前面的 00 就会消失。因此,我使用字符型来保存。可看
str(FL)
## chr [1:3] "600990" "300020" "29.3"
is.character(FL)
## [1] TRUE
默认参数
现在,我们得到了有关股票的代码与推荐价格的信息。接下来就是如何利用这少得可怜的输入参数来获得信息。
数据库选择
首先遇到的难题就是使用哪个数据库来获取股票信息。其实,现在网上有很多的免费数据可以提供了股票 OHLC 以及成交量的信息。但是信息不够齐全,要求我们在不同的数据库来回折腾。所幸,公司给我们配置了万得数据库。目前这个数据库自带的提供了 R 软件包,同时还提供了一系列的接口可以获取信息。这些信息囊括了股票行情、三大报表、公司基本情况等,算是做的不错的。因此,我觉得使用软件包 WindR 来解决数据的问题。
注意:由于我是在
Linux上面写博客,而现在万得只能运行在Windows系统下面。因此具体的代码运行结果也就无法实时展示。我尽量把在Windows系统下运行的结果转移过来。
下面代码是启动宏包:
library(WindR)
w.start(waitTime=60,showmenu=F)
代码转换
WindR 要求的股票代码必须以尾缀 .SH 或者 .SZ 来表示,而我们最初的输入代码只有数字(字符型),因此虚影相应的转换函数。
## 用于 WindR 代码格式转换
STOCK.CODE.WindR <- function(ticker){
if(substr(ticker, 1, 1) == 0|3)
TICKER <- paste(substr(ticker, 1, 6),".SZ", sep="")
if(substr(ticker, 1, 1) == 6)
TICKER <- paste(substr(ticker, 1, 6),".SH", sep="")
return(TICKER)
}
## 转换代码格式
ticker.transform <- function(x){
for(i in 1:2){
x[i] = STOCK.CODE.WindR(x[i])
}
return(x)
}
FL <- ticker.transform(FL)
WW <- ticker.transform(WW)
LYJ <- ticker.transform(LYJ)
WXZ <- ticker.transform(WXZ)
YYY <- ticker.transform(YYY)
###
R> FL
[1] "600990.SH" "300020.SZ" "29.3"
R> WW
[1] "300168.SZ" "600562.SH" "40"
R> LYJ
[1] "002594.SZ" "000768.SZ" "16"
R> WXZ
[1] "601766.SH" "601818.SH" "2.74"
R> YYY
[1] "600967.SH" "601002.SH" "11.25"
行情信息
下面就是这个函数的核心部分,以代码作为输入,来获取股票的行情信息。为了日后数据维护的方便,我把数据库分解开来,即第一支股票的基本情况,第二支股票的基本情况,以后两只股票汇总后的情况,这包括平均收益率,排名,得分等等。
第一支股票
第一支股票把股票的开盘价作为推荐价,因此可以没有推荐价显示。这个也方便平时同事们输入便捷、快速的习惯。
#########################################################################
## 第一支股票的基本情况:
## ticker1
#########################################################################
ticker1=c(FL[1], WW[1], LYJ[1], WXZ[1], YYY[1])
inf1 <- data.frame(ticker1,
name1 = rep(NA,5),
open1 = rep(0,5),
close1 = rep(0,5),
return1 = rep(0,5),
rank1 = rep(0,5),
Add.Score = rep(0,5))
##
for(i in 1:5){
inf1$name1[i] = w.wss(inf1$ticker1[i], 'sec_name')$Data$SEC_NAME ## 股票名称
inf1$open1[i] = w.wss(inf1$ticker1[i], 'pre_close,open,high,low,close', ## 开盘价
tradeDate = TradeDate)$Data$OPEN
inf1$close1[i] = w.wss(inf1$ticker1[i], 'pre_close,open,high,low,close', ## 收盘价
tradeDate = TradeDate)$Data$CLOSE
inf1$return1[i] = ( inf1$close1[i] - inf1$open1[i] ) / inf1$open1[i] * 100 ## 收益率
}
## 加分项设置
for(i in 1:5){
inf1$rank1[i] = which(sort(inf1$return1, decreasing = TRUE) == inf1$return1[i]) ## ticker1 排名
if(inf1$return1[i] >= 15){inf1$Add.Score[i] = 5}
else{
if(inf1$return1[i] >= 10){inf1$Add.Score[i] = 3}
else{
if(inf1$return1[i] >= 5){inf1$Add.Score[i] = 1}
else{
if(inf1$return1[i] > -5){inf1$Add.Score[i] = 0}
else{
if(inf1$return1[i] >= -10){inf1$Add.Score[i] = -1.5}
else inf1$Add.Score[i] = -3
}
}
}
}
}
第二支股票
第二支需要选择一个合适的时间点推荐的,因此需要把推荐价格当作输入。具体代码如下
#########################################################################
## 第二支股票的基本情况:
## ticker2
#########################################################################
ticker2 = c(FL[2], WW[2], LYJ[2], WXZ[2], YYY[2])
buy2 = as.numeric(c(FL[3], WW[3], LYJ[3], WXZ[3], YYY[3])) ## 第二支股票的建仓价: buy2
inf2 <- data.frame(ticker2,
name2 = rep(NA,5),
open2 = rep(0,5),
buy2,
close2 = rep(0,5),
return2 = rep(0,5),
rank2 = rep(0,5))
##
for(i in 1:5){
inf2$name2[i] = w.wss(inf2$ticker2[i], 'sec_name')$Data$SEC_NAME ## 股票名称
inf2$open2[i] = w.wss(inf2$ticker2[i], 'pre_close,open,high,low,close', ## 开盘价
tradeDate = TradeDate)$Data$OPEN
inf2$close2[i] = w.wss(inf2$ticker2[i], 'pre_close,open,high,low,close', ## 收盘价
tradeDate = TradeDate)$Data$CLOSE
inf2$return2[i] = ( inf2$close2[i] - inf2$buy2[i] ) / inf2$buy2[i] * 100 ## 收益率
}
for(i in 1:5){
inf2$rank2[i] = which(sort(inf2$return2, decreasing = TRUE) == inf2$return2[i]) ## ticker2 排名
}
汇总
下面就是把两只股票的信息做一个汇总
#########################################################################
## 两支股票的汇总情况: inf
## ticker1 + ticker2
#########################################################################
inf <- data.frame(Avr.Return = rep(0,5), ## 平均收益率
Rank = rep(0,5), ## 总排名
Rank.Score = rep(0,5), ## 排名得分
Total.Score = rep(0,5)) ## 总得分
for(i in 1:5){
inf$Avr.Return[i] = ( inf1$return1[i] + inf2$return2[i]) / 2
}
###
for(i in 1:5){
inf$Rank[i] = which(sort(inf$Avr.Return, decreasing = TRUE) == inf$Avr.Return[i])
if(inf$Rank[i] == 1)
inf$Rank.Score[i] = 2
else{
if(inf$Rank[i] == 2)
inf$Rank.Score[i] = 1
else
inf$Rank.Score[i] = 0
}
}
#########################################################################
## 汇总情况: df
## inf1 + inf2 + inf
#########################################################################
df <- data.frame()
df <- data.frame(t(rep(0,5)))
df <- cbind(inf1, inf2, inf)
for(i in 1:5){
df[i,18] = df[i,7] + df[i,17]
}
下面我们来看一下有什么惊喜呢。以下是我随意模拟的一个投资组合,看看他们在某个交易日的收益情况。从目前的结果来看,基本符合我们前期想要达到的效果。
R> df
ticker1 name1 open1 close1 return1 rank1 Add.Score
1 600990.SH 四创电子 44.68 44.93 0.560 1 0
2 300168.SZ 万达信息 27.49 27.60 0.400 2 0
3 002594.SZ 比亚迪 49.15 48.83 -0.651 5 0
4 601766.SH 中国南车 5.27 5.26 -0.190 3 0
5 600967.SH 北方创业 16.00 15.94 -0.375 4 0
ticker2 name2 open2 buy2 close2 return2 rank2
1 300020.SZ 银江股份 29.00 29.30 30.65 4.61 1
2 600562.SH 国睿科技 41.11 40.00 40.54 1.35 3
3 000768.SZ 中航飞机 15.79 16.00 15.79 -1.31 5
4 601818.SH 光大银行 2.77 2.74 2.77 1.09 4
5 601002.SH 晋亿实业 11.29 11.25 11.41 1.42 2
Avr.Return Rank Rank.Score Total.Score
1 2.584 1 2 2
2 0.875 2 1 1
3 -0.982 5 0 0
4 0.453 4 0 0
5 0.524 3 0 0
结果输入
以上我们得到了一个初步的结果。如何把我们实现的结果输入到合适的文本,这是一个一直困扰我的问题。
本人倾向于使用网页 (Html5 + css3),一来简单大方,可以使用 markdown 语法输入,二者通用性极强,基本上任何一台笔记本和手持移动设备都可以查看。可是我所在的公司似乎对这个先进性极强的新鲜事物抱着莫须有的排斥。也罢,道不同不相为谋。
他们更习惯习惯 MS 那套极其低效率与奇丑无比的 Office 套装。后来我能想到的唯一解就是放弃使用 Html, 改走 PDF 路线。也就是,PDF 也可以佯装 Word 的模样,既不灭了自己的志气,还涨了他人的威风,可谓一举两得。
LaTeX
以前读书的时候,把老师折磨的不行了,非得使用 Beamer 来制作 slide。幸好,也因此有缘结识 LaTeX 这个神一样的文档处理系统。她特别擅长与制作科学类的文档,同时也由于其具有良好的可控性,比较适合制作严格版面设计的文稿,这些文档具有高度的可重复利用价值,因此国际上几乎所有的期刊都要求作者提供 .tex 格式的论文稿件。
我一个初步的想法是使用 LaTeX 内在的编辑系统来生成 PDF 文件,通过设计一个文件模板使得这个文件具有可重复利用,以后每次要生成报告,就只需要输入股票代码就可以了,其他的版面控制全部交由模板来处理。
可是真正的使用 LaTeX 还是挺麻烦的,以前为了写一个助教课件,都得整整在图书馆泡着。满屏幕的代码,而且稍不注意,缺少个 } 啥的就彻底崩溃了,还得一个个检查看在哪一行出错。当年就是这样被虐千百遍才慢慢开始对其有了些许的驾驭能力。如今我已不入江湖,此般神功怕是荒废了时日,功力减退,深感「廉颇老矣」、屠龙不宜。
markdown
可是我这个人又喜欢「偷懒」,如果一件事情可以通过代码来事先,而不是机械的体力劳动,那么我会欣然去设计这样的程序的。作为半个码农的孩子又暴露了。
在目前我使用的文档编辑语言里面,markdown 可以是最简单明了、通俗易懂、老少咸宜,算得上了每个 hacker 必备的,可谓「居家旅行、杀人灭口、走亲访友、把妹泡茶」的神器。那么,我想要达到的效果就是
既可以享受
markdown带来的便捷,有可以利用LaTeX强大的文档编辑功能,达到「事半功倍」的效果。
LaTeX + markdown
冥冥之中必要答案!
以前陈海强老师给我们上时间序列课程的时候,使用 R 作为程序语言。可是陈老师似乎不怎么谈「用户体验」的高深问题,本来 R 自带的 GUI 就很丑,他还当着全班同学「群众贼亮的眼睛」、通过投影仪无极限的放大给大家看。当时我就很无言了。
后来有个叫做 Rstudio 的公司(神公司=大神+神器,以后有时间再详细讨论)开发了一款极其强调用户体用的 GUI,从知道的那一瞬间,我深深的「着迷」了。直到现在,还是一个在使用。
方为引子。下面进入正题。
刚才有提到我一直在使用 Rstudio。可是这有一个问题,一旦用习惯了某款极其好用的软件,便不舍得去改变,也不怎么去更新。以至于 Rstudio 后来增添了许多新功能,我也没来得及尝试。现在,Rstudio 已经高度融合了 knitr 与 markdown 的特征,通过软件包 rmarkdown 实现 LaTeX 与 markdown 的完美结合。整体的思路是:
- 首先建议一个
.Rmd的文件,里面可以使用markdown,同时配合R代码实现文学编程(literate programming)。 - 然后使用
pandoc转换.Rmd的文件,生成的是一个.tex文件。 - 最后,使用
LaTeX来实现 PDF 输出。
下面是一个例子,我们可以事先建立一个模板。
---
title: "荐股大赛"
author: 方莲
date: \cntoday
output:
pdf_document:
highlight: tango
keep_tex: yes
latex_engine: xelatex
number_sections: yes
template: set\advice_default.tex
toc: yes
toc_depth: 3
fig_height: 7
fig_width: 8
html_document:
toc: yes
pagecolor: aliceblue
---
模板(可以点击查看大图):






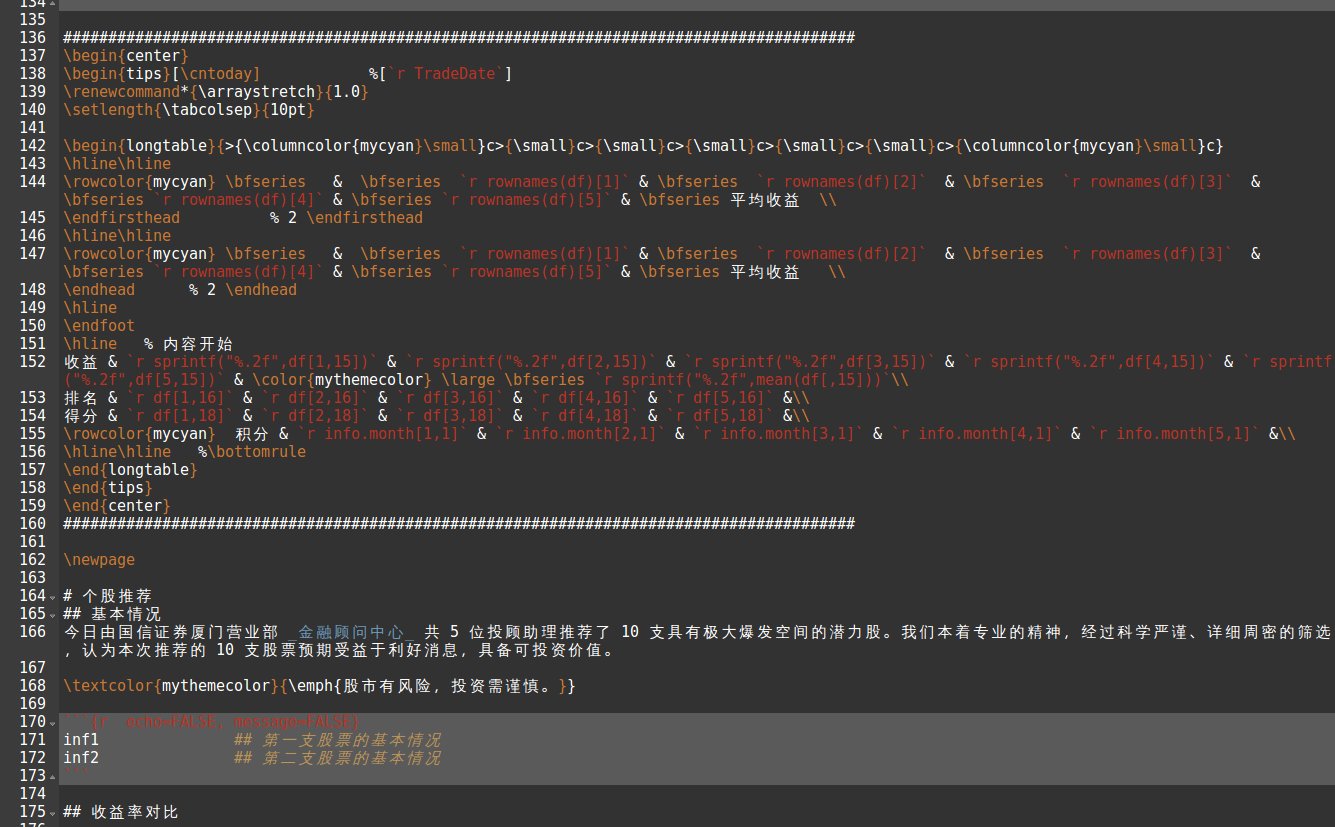

成果展示
通过以上模板,我们每次只需要输入参数,然后通过 Rstudio 即可自动生成一个像样的文件了。
