警告
本文最后更新于 2017-11-10,文中内容可能已过时。
我们已经实现了对两个交易所的数据爬虫(中金所、郑商所)。在技术层面上,这两个交易所都采用了静态网页的格式来呈现交易数据,这种类型的数据爬虫相对比较容易,我们只需要找到对应的数据文件地址,然后利用历史的交易日期来生成所有交易日的数据链接,然后开通并行计算模式即可下载到所有的历史数据。但对于上期所和大商所,二者则使用了相对复杂一些的动态网页技术,使用 AJAX 动态加载来显示数据。对这类网站进行数据爬虫,我们需要使用更加高级的技术手段。
本篇文章介绍如何对上期所进行动态网页数据的爬虫。
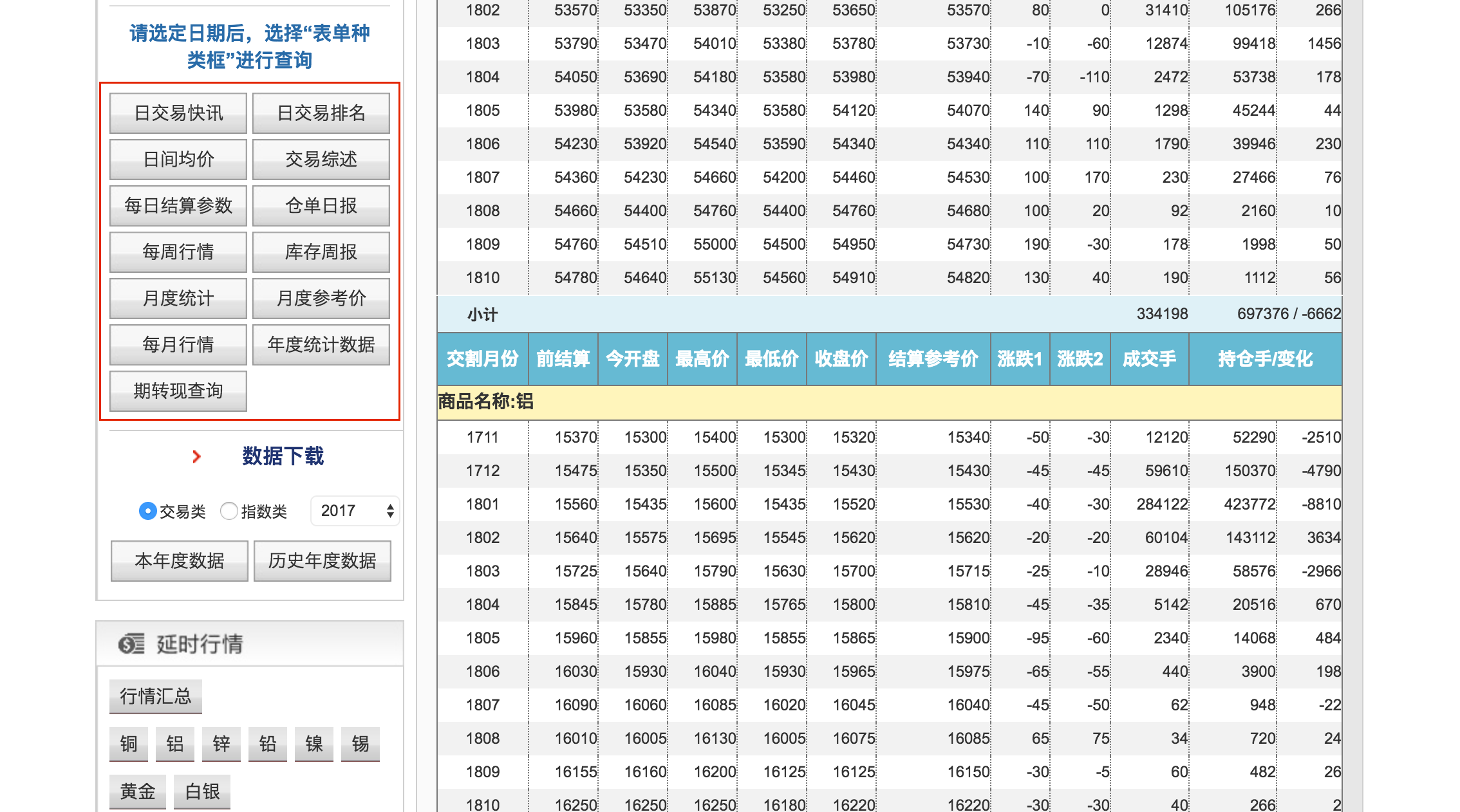
 上期所网站提供期货相关的数据
上期所网站提供期货相关的数据
日行情数据
我们首先打开交易数据相关的网页,可以看到上期所提供了大量的与期货交易相关的数据,其中包括日行情数据、交易排名数据等。点击选择 日交易快讯,我们便可以看到这一天的上期所期货合约日行情数据,具体的字段包括 OHLC、SettplementPrice、Volume等,不过没有 Turnover,这个算是有点遗憾,意味着我们无法使用上期所公布的当天的数据来计算 vwap。
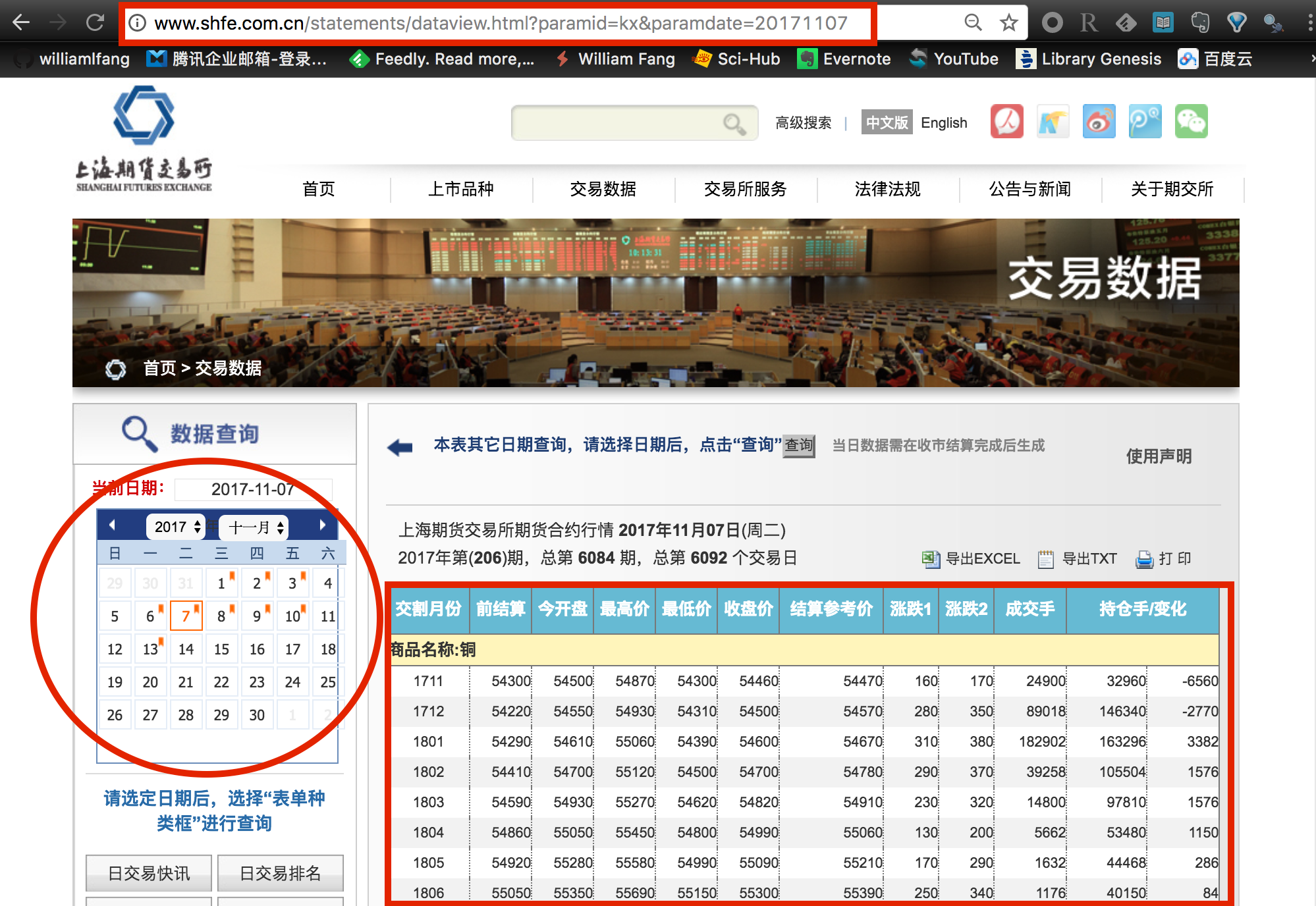 日行情数据
日行情数据
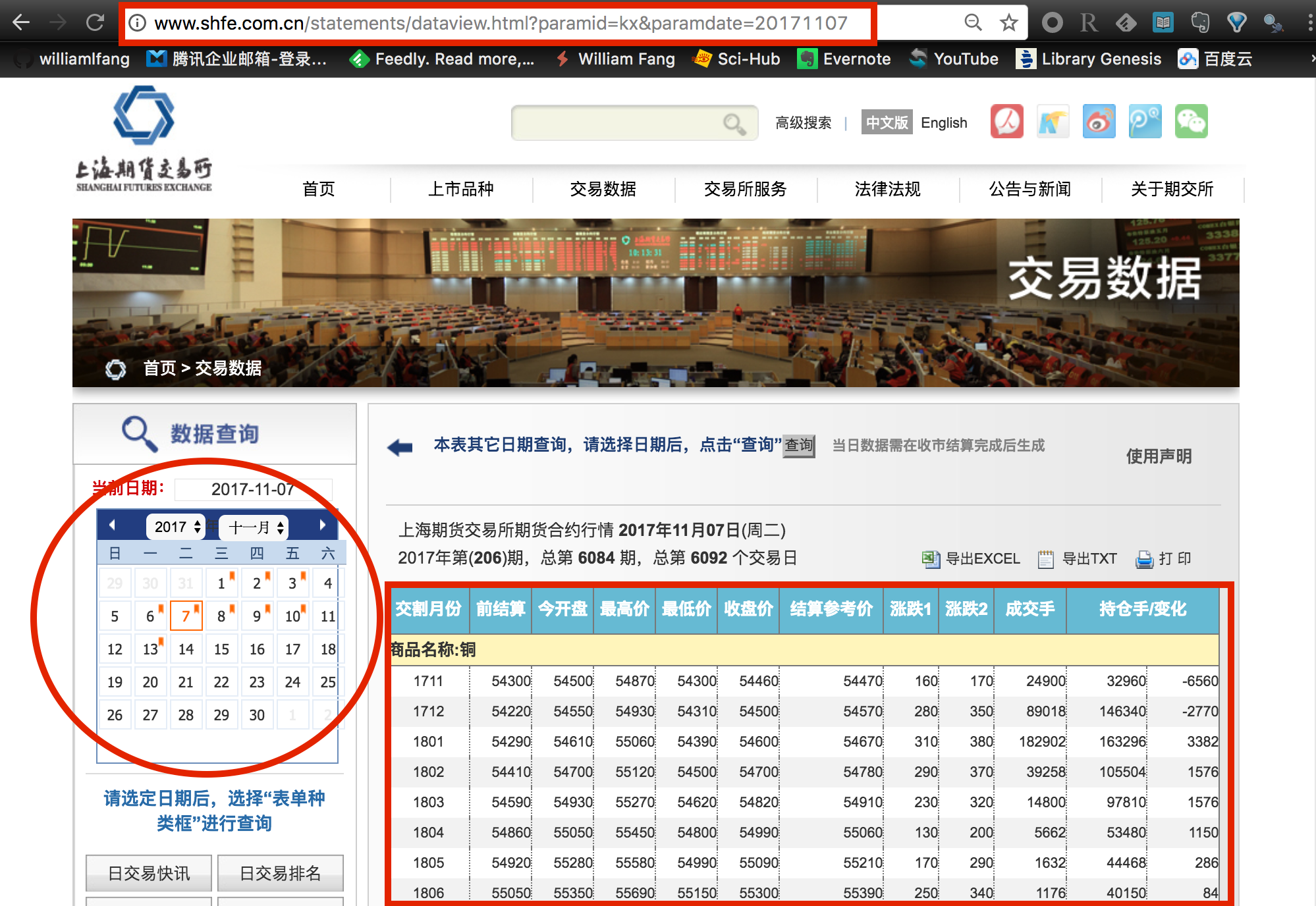
动态异步加载
我们试试通过左栏的日历表,选取不同交易日期的数据看看。各位注意到没有,我们点击了不同的网页链接,可以浏览器的地址栏的 paramdate= 这个字段也在随着发生改变。也就是说,我们可以使用历史所有的交易日期来生成不同的日行情网页链接,接下来只需要打开各个链接地址,就能看到具体的数据表格了。
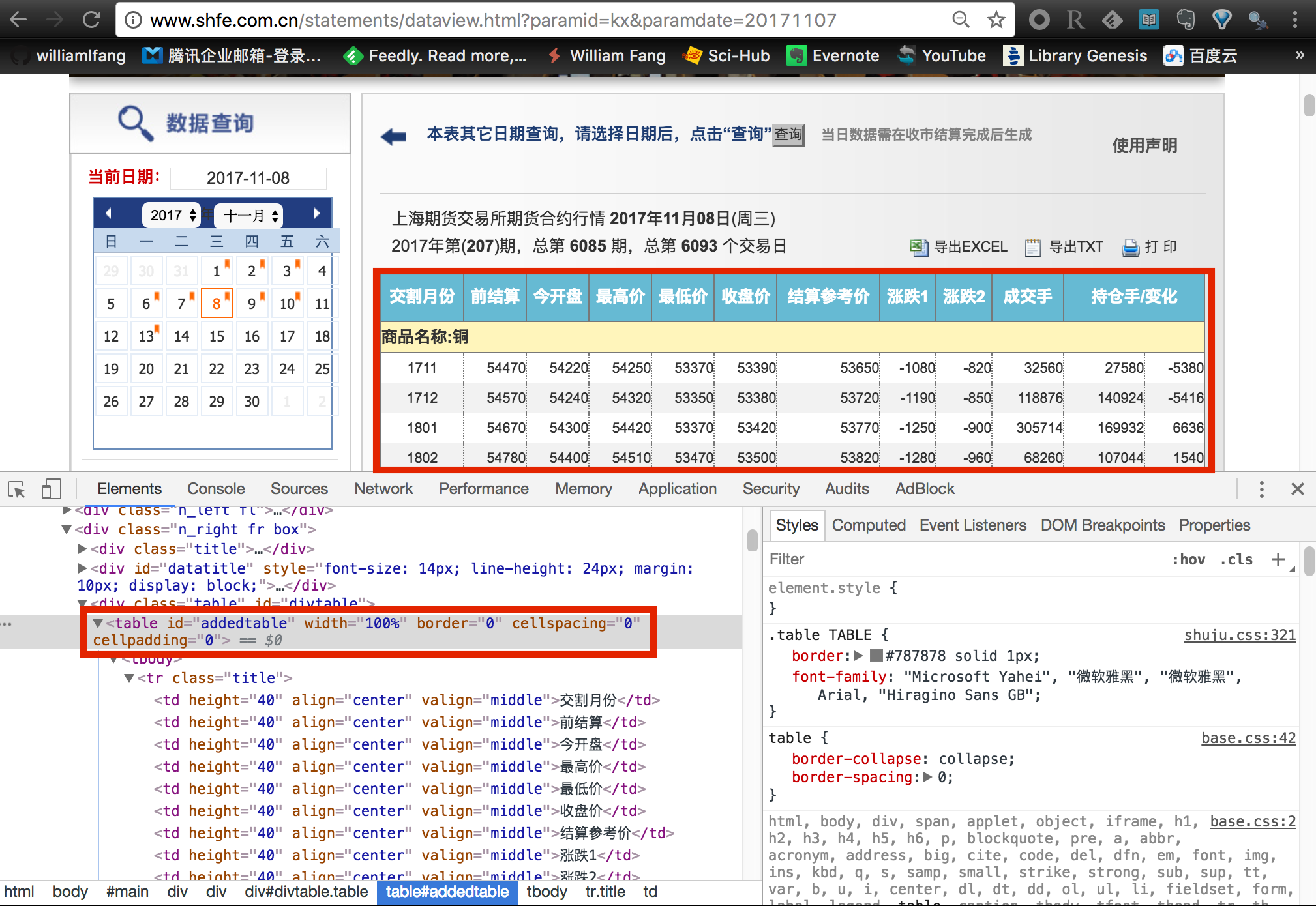
不过与我们之前介绍的中金所或郑商所不一样,后两家交易所是针对不同的交易日期提供了单独的数据界面,即我们所说的静态网页;而上期所采用的是动态异步加载的方式,我们使用鼠标选择好交易日期后,上期所服务器才发送数据给浏览器解析并呈现出来。因此,我们无法通过直接下载数据文件的链接来获取数据。
对于这类的动态网页爬虫,我们有两种方式可以处理:
- 如果熟悉
JavaScript 技术:可以通过编写 JavaScript 脚本来响应上期所服务器,进而截取数据
- 通过模拟鼠标的方式:确定好交易日期,等待远程服务器把数据传输到本地后,我们再对网页数据进行爬虫、读取、整理
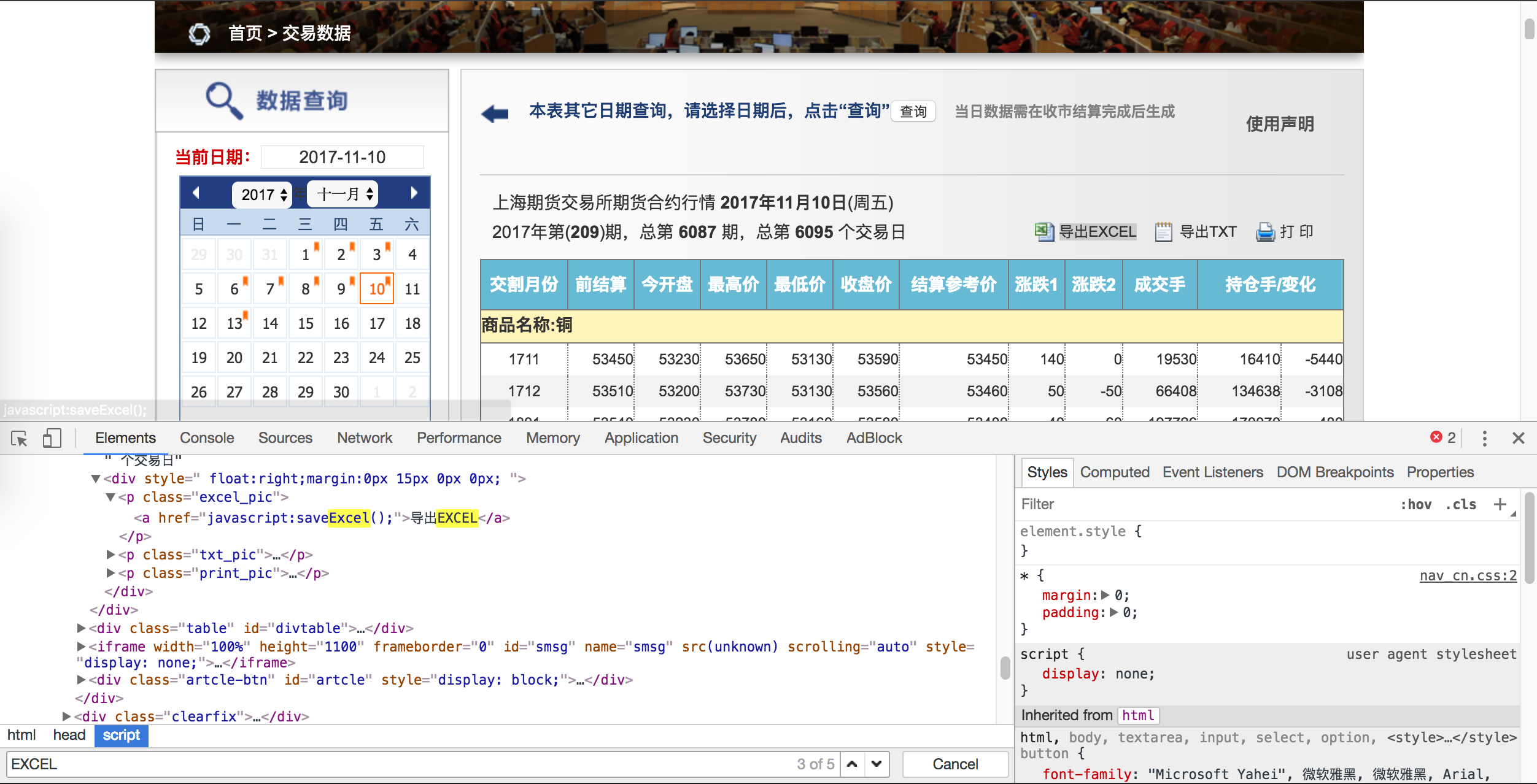 数据文件链接为动态格式
数据文件链接为动态格式
很显然,我不是 CS 科班,虽然有设计过博客,但也就是一般了解和基本使用的初级阶段,目前还无法掌握 JavaScript 的强大功能,而且也不打算为了数据爬虫专门去学习这门前段语言(一来中年危机之后的时间、精力受限,二来付出收益比不高)。因此,我使用了迂回策略,使用 Selenium 模拟鼠标来对上期所的交易数据进行爬虫。
看起来这个任务似乎挺复杂的。其实很简单(Maybe),我们只需要以下两个步骤:
- 定位交易日期
- 等服务器传送数据结束后,读取网页数据
定位交易日期
即利用历史的期货交易日期,生成单独的链接地址,然后使用 Selenium 驱动浏览器来打开网页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
## 开启 Selenium 和 firefox
remDr <- remoteDriver(remoteServerAddr ='localhost'
,port = 4444
,browserName = 'firefox')
remDr$getStatus()
## 生成链接地址
exchURL <- "http://www.shfe.com.cn/statements/dataview.html?paramid=kx¶mdate="
tempURL <- paste0(exchURL, exchCalendar[i,days])
## 在浏览器打开链接来获取远程服务器数据
## ===========================================================================
## 开始准备下载数据
# 需要保持开启
# ----------------------------------------------------------------------------
remDr$open(silent = TRUE)
remDr$navigate(tempURL)
Sys.sleep(0.5)
|
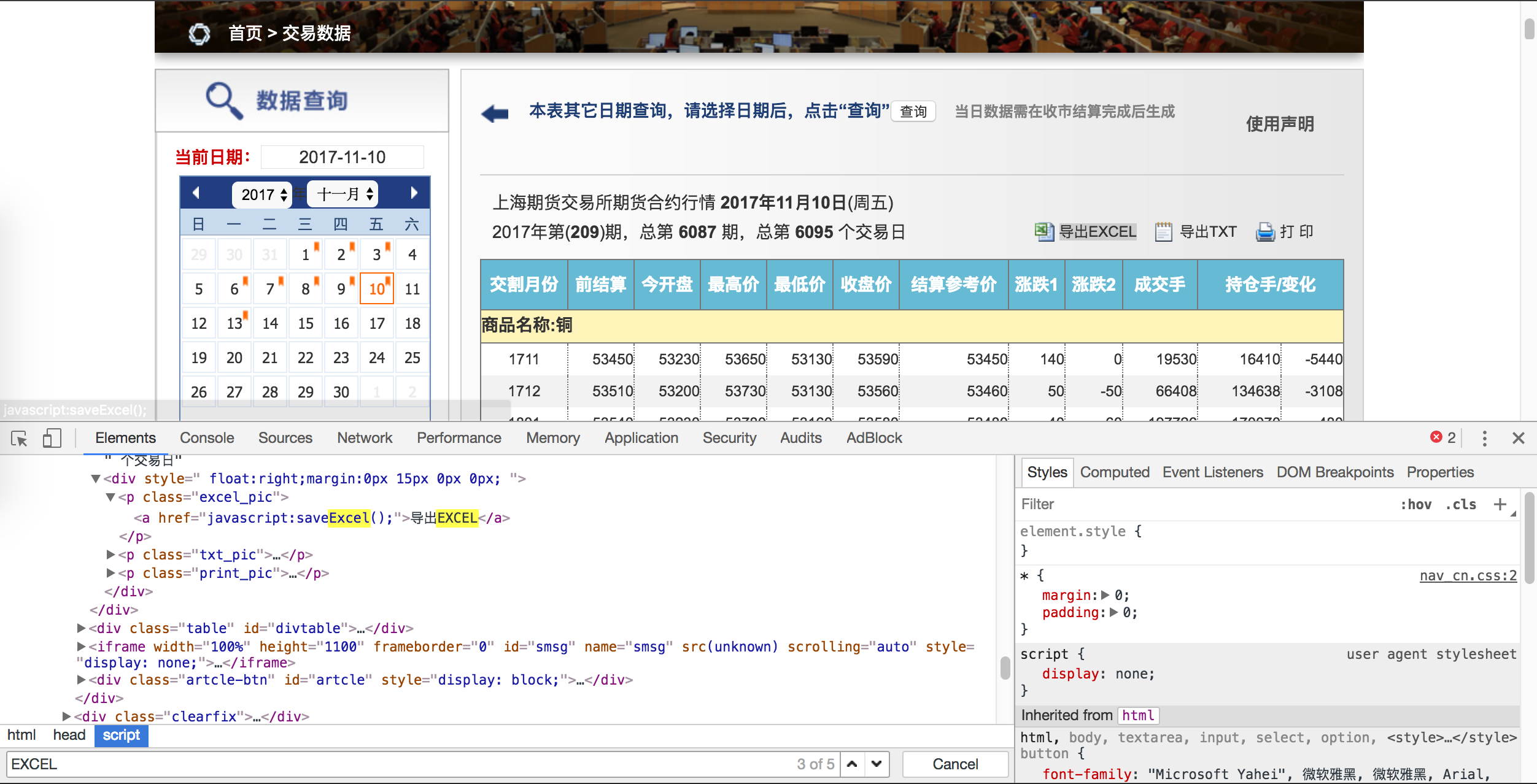
读取网页数据
到目前为止,我们能够看到在 firefox 浏览器已经打开了当前的日行情数据网页。接下来,我们需要对网页进行数据爬虫。
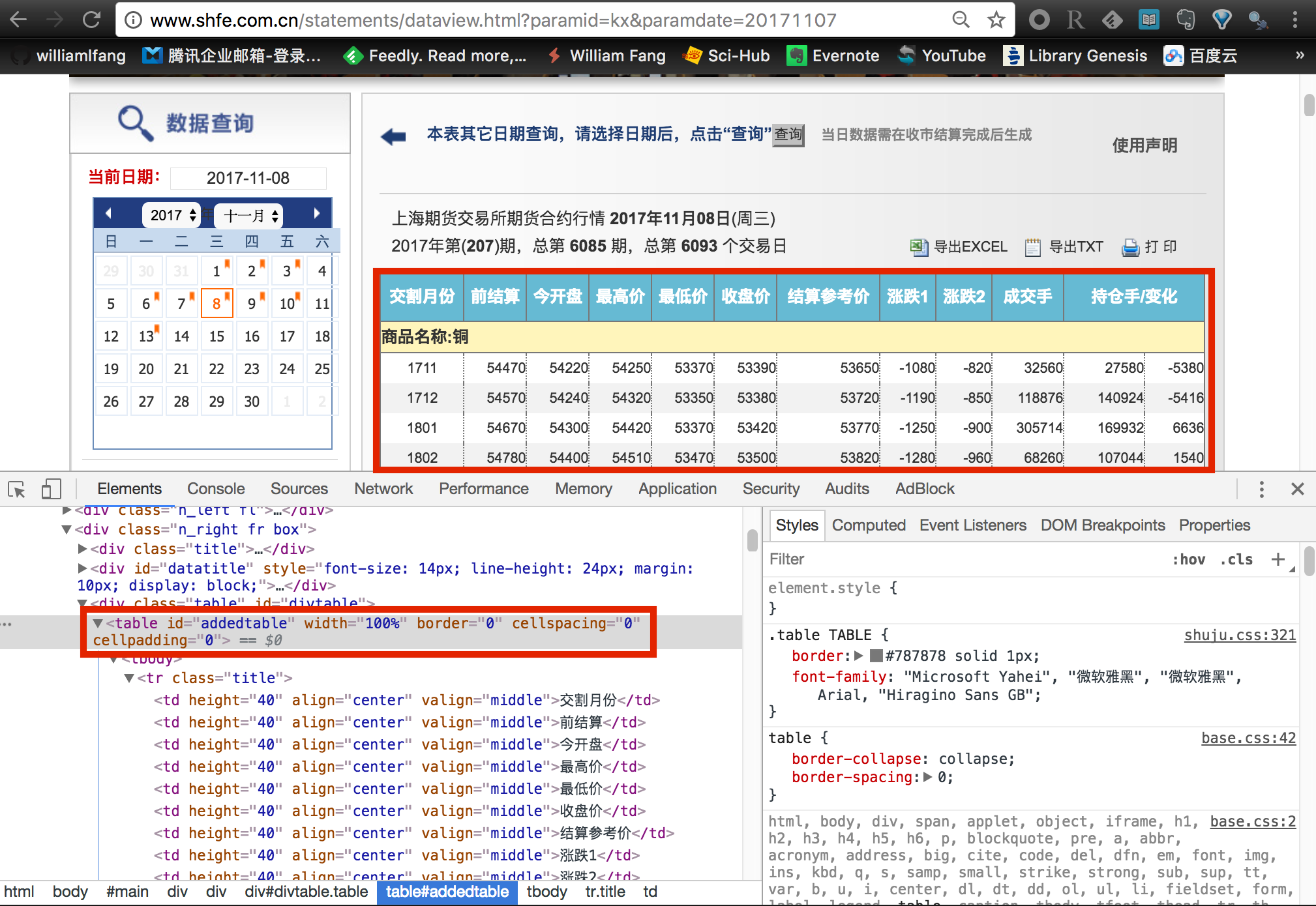 找到数据所在的节点
找到数据所在的节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
## ---------------------------------------------------------------------------
tempTitle <- remDr$findElements(using = 'id', value = 'datatitle')[[1]]
tempQueryDay <- tempTitle$getElementAttribute('outerHTML')[[1]] %>%
read_html(encoding = 'GB18030') %>%
html_node('strong') %>%
html_text() %>%
gsub('\\D','',.)
if (tempQueryDay != exchCalendar[i,days]) return(NULL)
## ---------------------------------------------------------------------------
## ---------------------------------------------------------------------------
#-- 找到数据
tempTable <- remDr$findElements(using = 'id', value = 'addedtable')[[1]]
webData <- tempTable$getElementAttribute('outerHTML')[[1]] %>%
read_html(encoding = 'GB18030') %>%
html_nodes('table') %>%
html_table(fill = TRUE, header=FALSE) %>%
as.data.table() %>%
.[-grep('注:|报价单位',X1)]
print(webData)
## ---------------------------------------------------------------------------
|
剩下的就是把数据保存为文件了,并记得把相关的进程结束掉,否则会一直占有系统内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
## ---------------------------------------------------------------------------
tryNo <- 0
while ( (!file.exists(destFile) | file.size(destFile) < 1000) & (tryNo < 10) ){
openxlsx::write.xlsx(webData, file = destFile,
colNames = FALSE, rowNames = FALSE)
tryNo <- tryNo + 1
}
## ===========================================================================
## 关闭浏览器
try({
system('pkill -f firefox')
system('pkill -f geckodriver')
system('rm -rf /tmp/rust_mozprofile*')
})
## ===========================================================================
|
完整的 Demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
|
################################################################################
##! shfe.R
## 这是主函数:
## 用于从 上期所 网站爬虫期货交易的日行情数据
## daily
##
##
## 注意:
##
## Author: fl@hicloud-investment.com
## CreateDate: 2017-10-16
################################################################################
################################################################################
## STEP 0: 初始化,载入包,设定初始条件
################################################################################
rm(list = ls())
logMainScript <- c("shfe.R")
if (class(try(setwd('/home/fl/myData/'))) == 'try-error') {
setwd('/run/user/1000/gvfs/sftp:host=192.168.1.166,user=fl/home/fl/myData')
}
suppressMessages({
source('./R/Rconfig/myInit.R')
})
library(RSelenium)
################################################################################
## STEP 1: 获取对应的交易日期
################################################################################
ChinaFuturesCalendar <- fread("./data/ChinaFuturesCalendar/ChinaFuturesCalendar.csv",
colClasses = list(character = c("nights","days"))) %>%
.[days < format(Sys.Date(),'%Y%m%d')]
exchCalendar <- ChinaFuturesCalendar[,":="(calendarYear = substr(days,1,4),
calendarYearMonth = substr(days,1,6),
calendarMonth = substr(days,5,6),
calendarDay = substr(days,7,8))]
dataPath <- '/home/william/Documents/Exchange/SHFE/'
# dataPath <- "./data/Bar/Exchange/SHFE/"
##------------------------------------------------------------------------------
if(Sys.info()['sysname'] == 'Windows'){
Sys.setenv("R_ZIPCMD" = "D:/Program Files/Rtools/bin/zip.exe") ## path to zip.exe
}
##------------------------------------------------------------------------------
################################################################################
## SHFE: 上期所
exchURL <- "http://www.shfe.com.cn/statements/dataview.html?paramid=kx¶mdate="
################################################################################
################################################################################
## 后台开启一下命令
##
## cd Desktop
## java -jar selenium-server-standalone-3.0.0.jar
##
################################################################################
remDr <- remoteDriver(remoteServerAddr ='localhost'
,port = 4444
,browserName = 'firefox')
remDr$getStatus()
#
#
################################################################################
## 开始下载数据
################################################################################
shfeData <- function(i) {
## ===========================================================================
tempDir <- paste0(dataPath,exchCalendar[i,calendarYear])
if (!dir.exists(tempDir)) dir.create(tempDir, recursive = TRUE)
## ===========================================================================
tempURL <- paste0(exchURL, exchCalendar[i,days])
## ===========================================================================
## 判断文件是不是已经下载了
## ---------------------------------------------------------------------------
destFile <- paste0(tempDir, "/",
ChinaFuturesCalendar[i,days],".xlsx")
if (file.exists(destFile)) return(NULL)
## ===========================================================================
## ===========================================================================
## 开始准备下载数据
# 需要保持开启
# ----------------------------------------------------------------------------
remDr$open(silent = TRUE)
remDr$navigate(tempURL)
Sys.sleep(0.5)
## ---------------------------------------------------------------------------
tempTitle <- remDr$findElements(using = 'id', value = 'datatitle')[[1]]
tempQueryDay <- tempTitle$getElementAttribute('outerHTML')[[1]] %>%
read_html(encoding = 'GB18030') %>%
html_node('strong') %>%
html_text() %>%
gsub('\\D','',.)
if (tempQueryDay != exchCalendar[i,days]) return(NULL)
## ---------------------------------------------------------------------------
## ---------------------------------------------------------------------------
#-- 找到数据
tempTable <- remDr$findElements(using = 'id', value = 'addedtable')[[1]]
webData <- tempTable$getElementAttribute('outerHTML')[[1]] %>%
read_html(encoding = 'GB18030') %>%
html_nodes('table') %>%
html_table(fill = TRUE, header=FALSE) %>%
as.data.table() %>%
.[-grep('注:|报价单位',X1)]
print(webData)
## ---------------------------------------------------------------------------
tryNo <- 0
while ( (!file.exists(destFile) | file.size(destFile) < 1000) & (tryNo < 10) ){
openxlsx::write.xlsx(webData, file = destFile,
colNames = FALSE, rowNames = FALSE)
tryNo <- tryNo + 1
}
## ===========================================================================
## 关闭浏览器
try({
system('pkill -f firefox')
system('pkill -f geckodriver')
system('rm -rf /tmp/rust_mozprofile*')
})
## ===========================================================================
}
################################################################################
## STEP 2: 开启并行计算模式,下载数据
################################################################################
# cl <- makeCluster(max(round(detectCores()*3/4),4), type='FORK')
# parSapply(cl, 1:10, function(i){
# ## ---------------------------------------------------------------------------
# try(shfeData(i))
# ## ---------------------------------------------------------------------------
# })
# stopCluster(cl)
## =============================================================================
sapply(1:nrow(ChinaFuturesCalendar),shfeData)
## =============================================================================
|
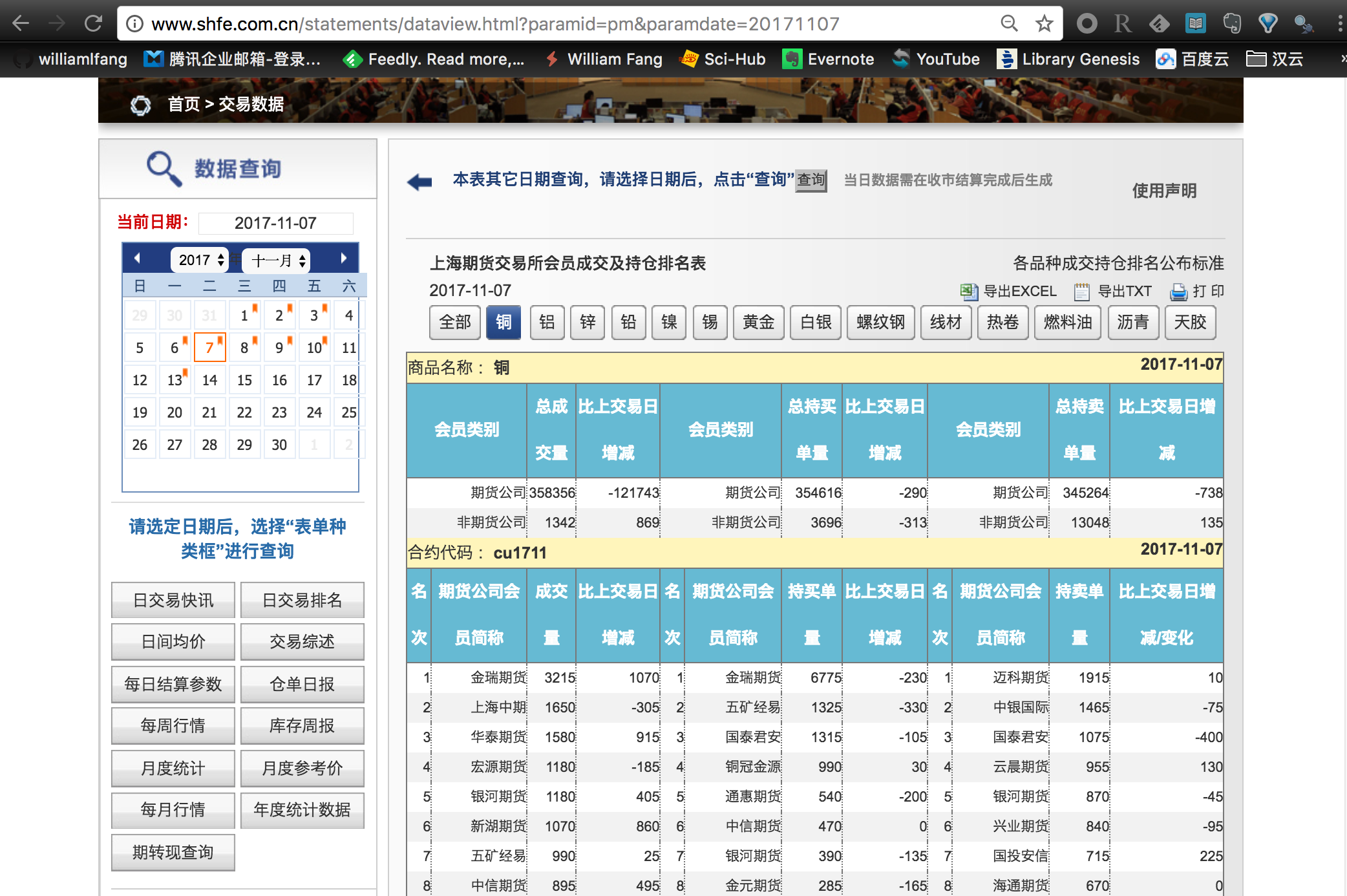
成交持仓排名
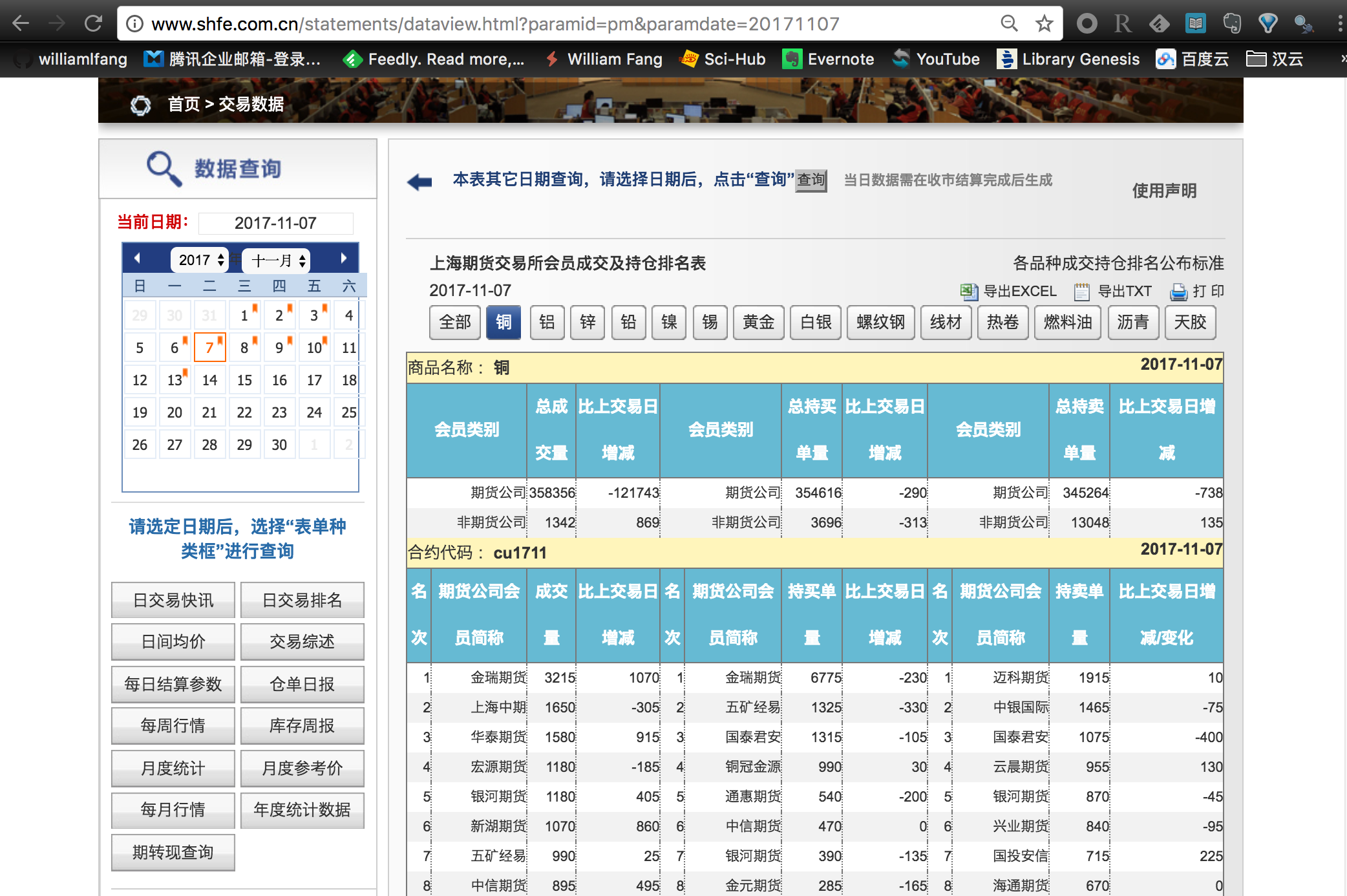 成交持仓排名数据
成交持仓排名数据
与日行情数据相类似的,我们也可以使用这种方法来爬虫期货公司的成交持仓排名数据。这里只需要把相对的链接地址更改一下即可。
1
2
3
|
## 改为 pm
exchURL <- "http://www.shfe.com.cn/statements/dataview.html?paramid=pm¶mdate="
tempURL <- paste0(exchURL, exchCalendar[i,days])
|
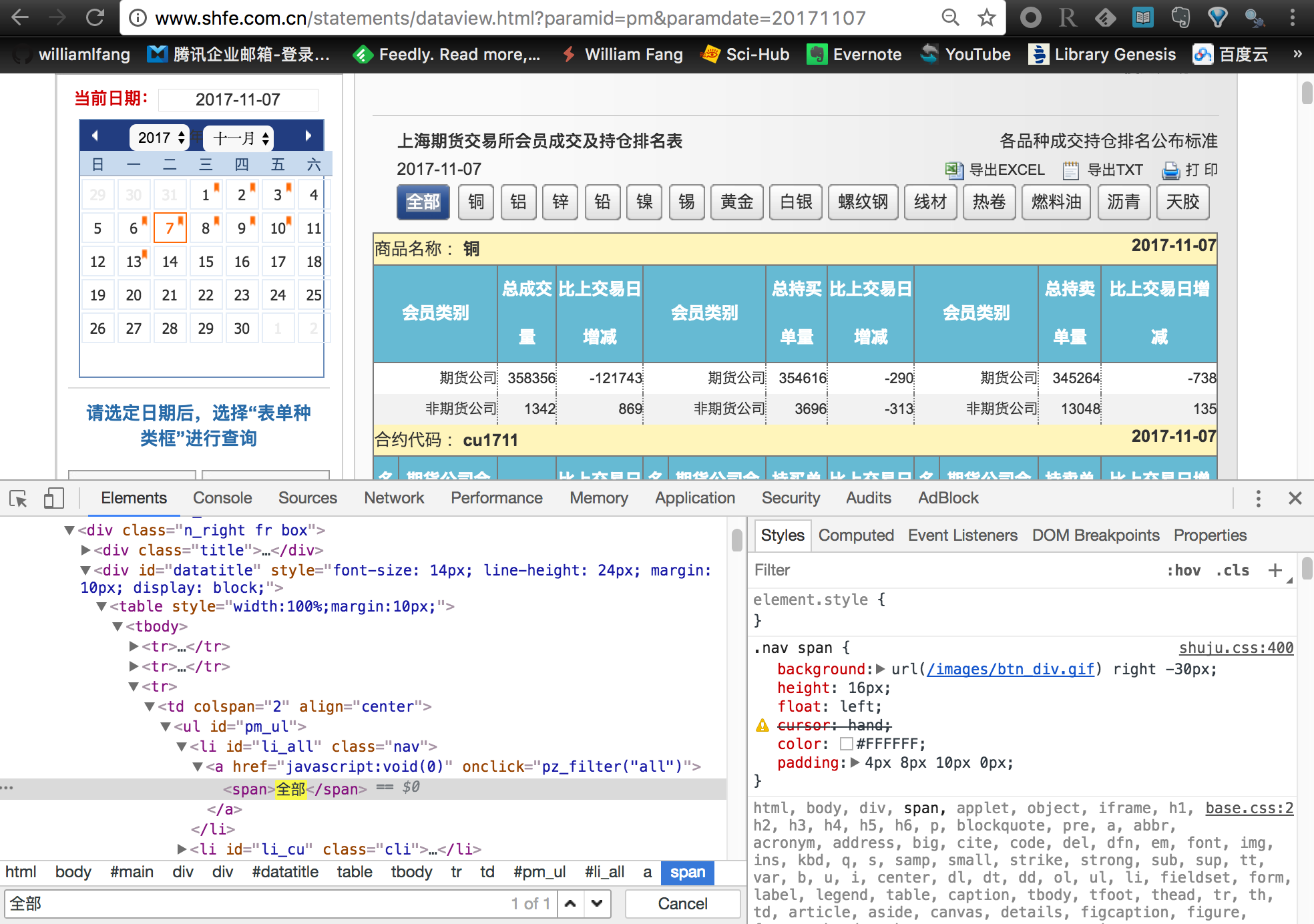
选择全部合约
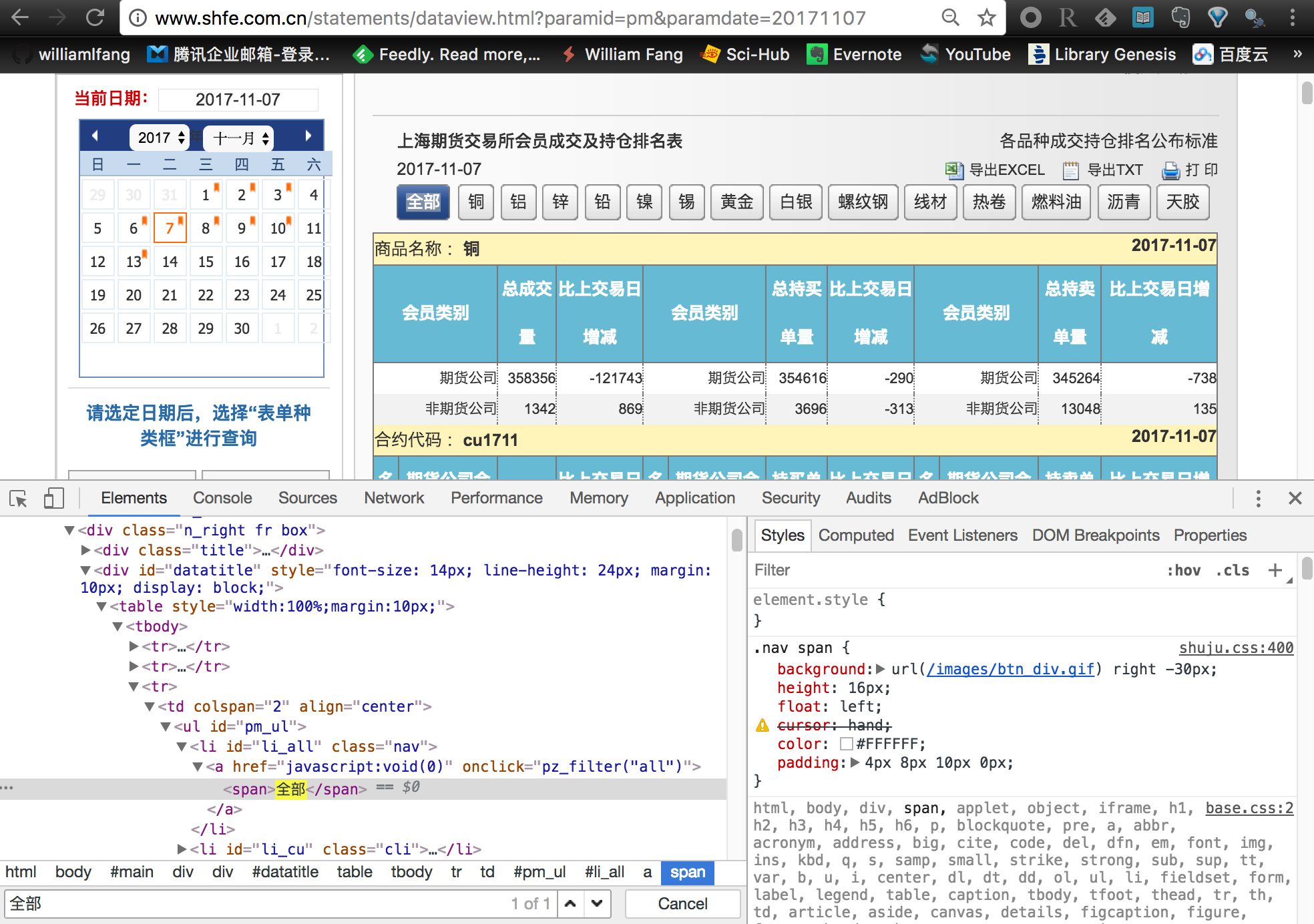 需要选择上期所全部期货合约
需要选择上期所全部期货合约
不过,上期所提供的默认传送数据是 铜,如果只是简单粗暴的爬虫,只能获取铜期货合约的单个数据。注意到旁边还有一个 全部 的按钮,我们点击这个按钮后服务器才会把所有合约的成交持仓排名数据传输到本地。因此,我们在爬虫之前还需要模拟鼠标点击选择全部合约的按钮。这个也是可以通过 Selenium 来实现。具体的做法是
- 首先,定位
全部 按钮所对应的节点
- 然后使用
clickElement() 函数模拟鼠标单击操作
具体的代码如下
1
2
3
4
5
|
## 定位全部合约的按钮
temp <- remDr$findElements(using = 'id', value = 'li_all')[[1]]
#-- 点击选择全部合约
tempWeb <- temp$clickElement()
|
现在,我们就能在本地获取所有合约的成交持仓排名数据了。对网页进行数据爬虫与上面的日行情数据爬虫一样,不再赘述。
完整的 Demo
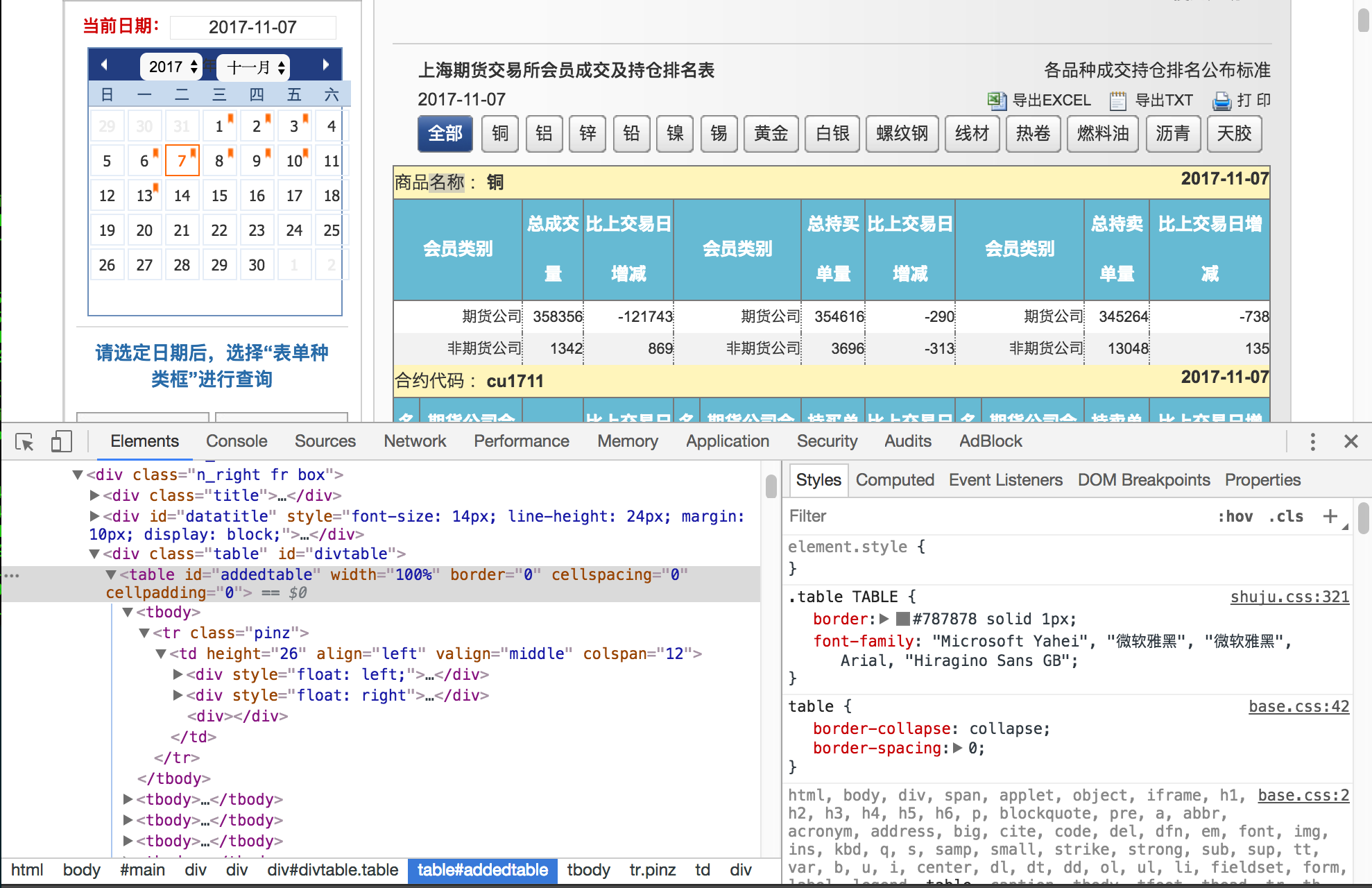
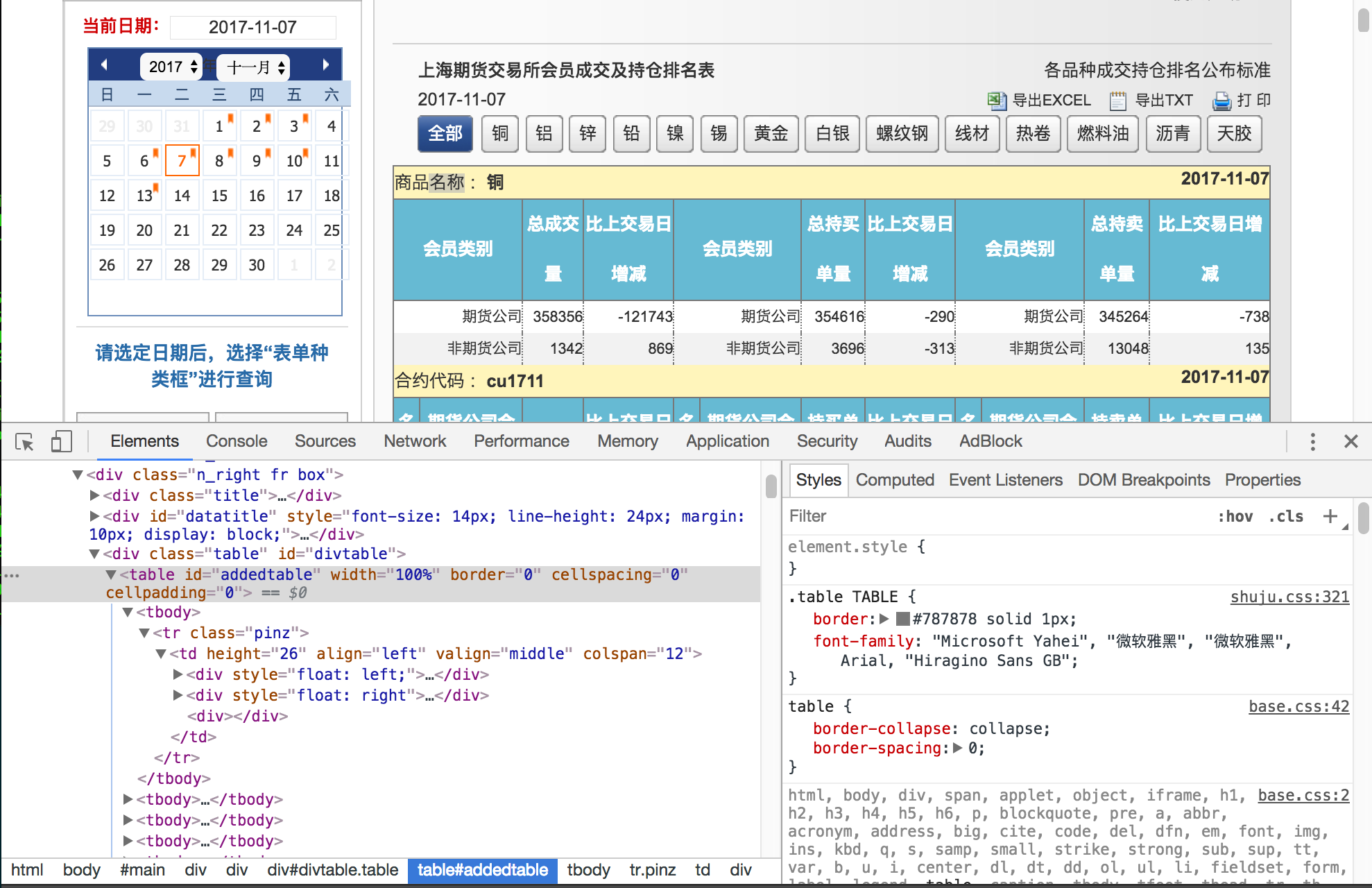 成交持仓排名的网页结构
成交持仓排名的网页结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
|
################################################################################
## shfe.R
## 用于下载上期所期货公司持仓排名数据
##
## Author: William Fang
## Date : 2017-08-21
################################################################################
################################################################################
## STEP 0: 初始化,载入包,设定初始条件
################################################################################
rm(list = ls())
logMainScript <- c("shfe.R")
if (class(try(setwd('/home/fl/myData/'))) == 'try-error') {
setwd('/run/user/1000/gvfs/sftp:host=192.168.1.166,user=fl/home/fl/myData')
}
suppressMessages({
source('./R/Rconfig/myInit.R')
})
library(RSelenium)
################################################################################
## STEP 1: 获取对应的交易日期
################################################################################
ChinaFuturesCalendar <- fread("./data/ChinaFuturesCalendar/ChinaFuturesCalendar.csv",
colClasses = list(character = c("nights","days"))) %>%
.[days < format(Sys.Date(),'%Y%m%d')]
exchCalendar <- ChinaFuturesCalendar[,":="(calendarYear = substr(days,1,4),
calendarYearMonth = substr(days,1,6),
calendarMonth = substr(days,5,6),
calendarDay = substr(days,7,8))]
dataPath <- '/home/william/Documents/oiRank/SHFE/'
# dataPath <- "./data/Bar/oiRank/SHFE/"
##------------------------------------------------------------------------------
if(Sys.info()['sysname'] == 'Windows'){
Sys.setenv("R_ZIPCMD" = "D:/Program Files/Rtools/bin/zip.exe") ## path to zip.exe
}
##------------------------------------------------------------------------------
################################################################################
## SHFE: 上期所
exchURL <- "http://www.shfe.com.cn/statements/dataview.html?paramid=pm¶mdate="
################################################################################
################################################################################
## 后台开启一下命令
##
## cd Desktop
## java -jar selenium-server-standalone-3.0.0.jar
##
################################################################################
remDr <- remoteDriver(remoteServerAddr ='localhost'
,port = 4444
,browserName = 'firefox')
remDr$getStatus()
#
#
################################################################################
## 开始下载数据
## 1.持仓排名
################################################################################
shfeData <- function(i) {
## ===========================================================================
tempDir <- paste0(dataPath,exchCalendar[i,calendarYear])
if (!dir.exists(tempDir)) dir.create(tempDir, recursive = TRUE)
## ===========================================================================
tempURL <- paste0(exchURL, exchCalendar[i,days])
## ===========================================================================
## 判断文件是不是已经下载了
## ---------------------------------------------------------------------------
destFile <- paste0(tempDir, "/",
ChinaFuturesCalendar[i,days],".xlsx")
if (file.exists(destFile)) return(NULL)
## ===========================================================================
## ===========================================================================
## 开始准备下载数据
# 需要保持开启
# ----------------------------------------------------------------------------
remDr$open(silent = TRUE)
remDr$navigate(tempURL)
Sys.sleep(1)
## ---------------------------------------------------------------------------
tempTitle <- remDr$findElements(using = 'id', value = 'datatitle')[[1]]
tempQueryDay <- tempTitle$getElementAttribute('outerHTML')[[1]] %>%
read_html(encoding = 'GB18030') %>%
html_nodes('table') %>%
html_table() %>%
.[[1]] %>%
.[2, 'X1'] %>%
gsub('-','',.)
if (tempQueryDay != exchCalendar[i,days]) return(NULL)
## ---------------------------------------------------------------------------
temp <- remDr$findElements(using = 'id', value = 'li_all')[[1]]
#-- 点击选择全部合约
tempWeb <- temp$clickElement()
Sys.sleep(1)
#-- 找到数据
tempData <- remDr$findElements(using = 'id', value = 'addedtable')[[1]]
webData <- tempData$getElementAttribute('outerHTML')[[1]] %>%
read_html() %>%
html_node('table') %>%
html_table(fill = TRUE)
tryNo <- 0
while ( (!file.exists(destFile) | file.size(destFile) < 1000) & (tryNo < 10) ){
openxlsx::write.xlsx(webData, file = destFile,
colNames = FALSE, rowNames = FALSE)
tryNo <- tryNo + 1
}
## ===========================================================================
## 关闭浏览器
try({
system('pkill -f firefox')
system('pkill -f geckodriver')
system('rm -rf /tmp/rust_mozprofile*')
})
## ===========================================================================
}
## =============================================================================
sapply(1:nrow(ChinaFuturesCalendar),shfeData)
## =============================================================================
|
 william 收录于 Data
william 收录于 Data
 支付宝
支付宝
 微信
微信