本文最后更新于 2017-10-28,文中内容可能已过时。
上回我介绍了如何对中金所进行网络爬虫 ,获得了股指期货相关的历史日行情数据和成交排名数据。同样的,我们也可以使用类似的爬虫技术,对郑商所进行网络爬虫。
不过与中金所网络爬虫不一样的一点是,中金所本身提供了数据文件的静态链接地址 ,我们只需要解析到不同交易日期所对应的链接,就能够把数据下载到本地。而郑商所虽然也同样提供了文件的静态链接,但是 ,我在爬虫的过程中发现了一个小小的问题:有部分的交易数据,郑商所不知道出于何种原因(有可能是原始的数据文件丢失,或者路径存储错误),竟然找不到当日对应的数据文件链接。也就是说,对于这些交易日,我们是无法直接下载文件的。因此,对于这些没有提供链接的数据,我们只能采用页面爬虫的技术,通过读取网页的数据,经过数据清理、规整等步骤,再保存到本地文件。
针对网站页面的数据进行爬虫,会涉及到 DOM 构造、HTML 元素解析、文本识别、正则表达等诸多方面的技术。在接下来的内容里,我会重点介绍如何在网页中找到我们需要的数据。
郑商所网站提供期货与期权相关的数据
对于网页内容进行爬虫、识别网页内容、获取目标数据或文本等,我们需要使用到 HTML 相关的技术手段。最原始的一种办法是通过 wget 把整个网页下载到本地,然后再进行内容解析;或者使用 libcur 来读取远程的内容并传递到系统的内存。这些技术难度较大,而且得到的数据并不是结构性的,使用正则获取目标数据比较坎坷。万幸的是,已经有人通过软件包的形式,为我们把这些基础的工作都处理完成了,我们只需要调用相关的函数,即可实现简单的网页爬虫。
以下两个 R 的扩展包就是针对网络爬虫而开发的。
RSelenium Selenium 是一款网络驱动,作为无头浏览器 (headless webdriver)驱动,提供了高性能的网络测试、页面加载、网络解析等功能。基于这项技术所提供的 API 调用端口,我们可以使用不同的编程语言来调用浏览器功能,从而实现了开发-测试的无缝连接。
RSelenium 就是 Selenium 在 R 语言下的扩展包,集成了大量可供调用的函数,使得我们只需要在 R 中调用函数并传入参数,即可对网页进行解析。
rvest 这个是大神 Wickham Hadley 编写的一个针对网页爬虫的扩展包,封装了 Linux 下的 libcur 库,因此能够提供对网页页面的 DOM 解析。这个包返回一个结构化的对象,可以通过 R 的函数对其进行数据清理;同时它还针对不同的编码进行自动化的识别,这点对于中文网站尤其重要,否则,编码错误会导致我们爬虫的数据出现乱码的悲剧。
我们在对中金所进行爬虫的那篇博客里面,已经讲到如何通过 Chrome 的 Inspect 功能来获取网页的元素。通过查找特定位置的 HTML 标签,我们可以得到该位置所对应的具体信息。
首先我们需要做的是先尝试定位某个交易日的日行情数据存放网页,通过输入交易日,然后点击查询,我们便可以看到需要查找的交易数据。
通过交易日期查找日行情数据
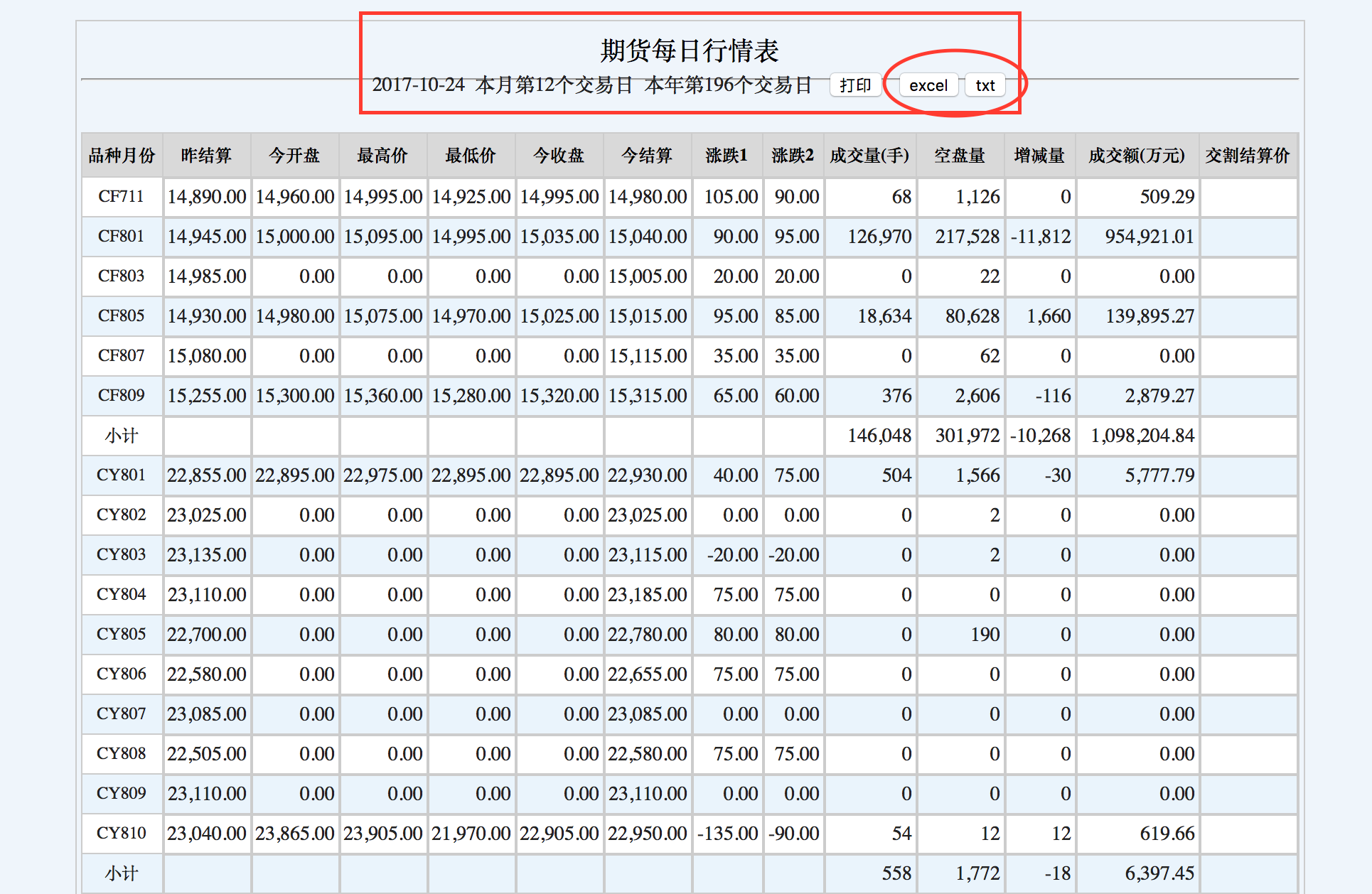
这个便是我们需要进行爬虫的单独网页。
承载数据的具体网页
我们来看看当天的网页地址,比如:http://www.czce.com.cn/portal/DFSStaticFiles/Future/2017/20171026/FutureDataDaily.htm。主要是由以下几个部分组成的:
http://www.czce.com.cn/portal/DFSStaticFiles/Future/:这个可以当成是日行情的根目录。2017/20171026/FutureDataDaily.htm:这个命名规则很明显,由 YYYY/YYYYmm/FutureDataDaily.htm 构成。我们可以根据交易日来提取日期组成。
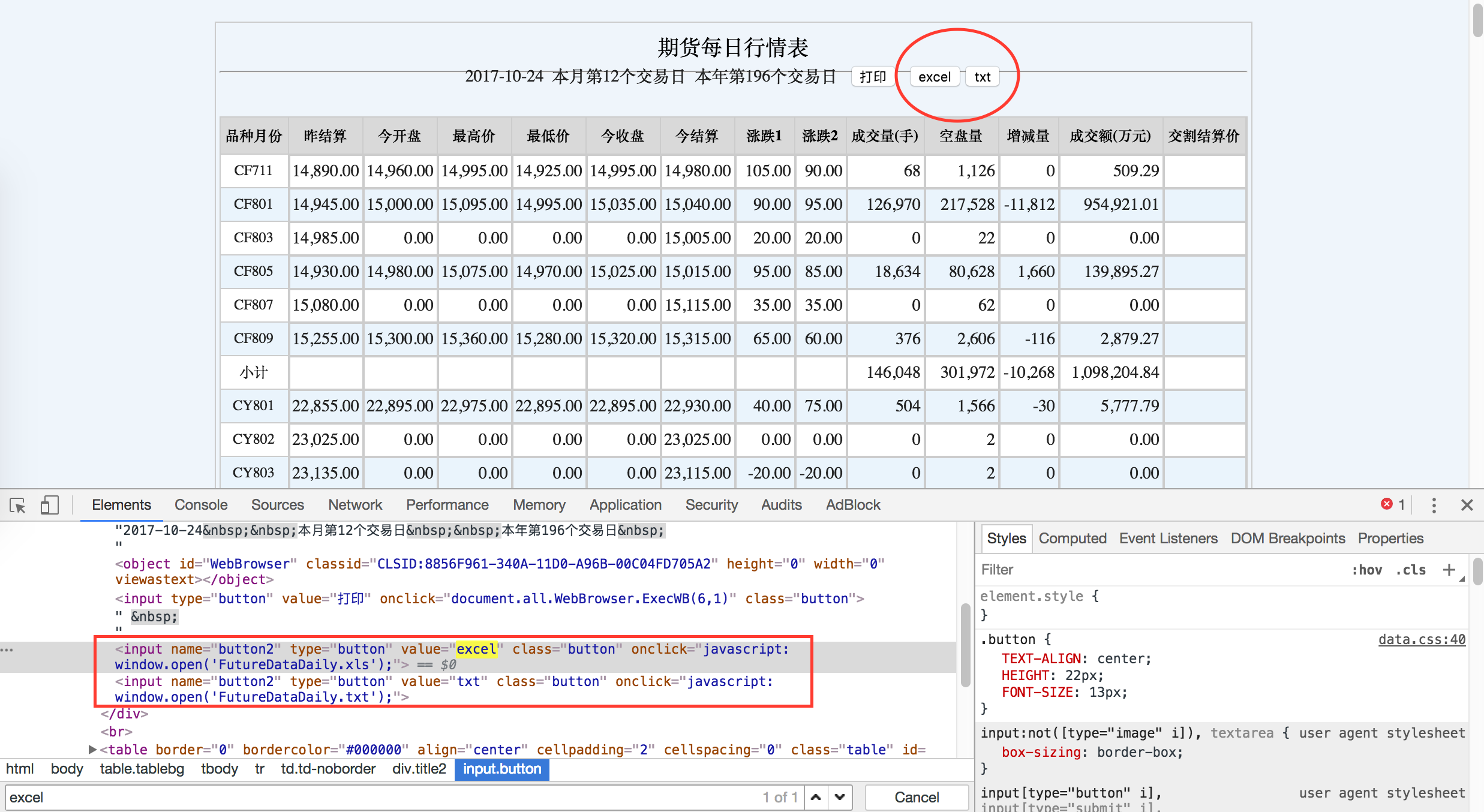
在数据文件对应的 excel / txt 点击右键,然后使用 Ctrl + F 查找 excel,我们便可以定位到数据文件了。
通过元素审查获取标签的具体信息
一看吓一跳,似乎这个数据文件是一个动态的脚本,好像很难识别的样子。不过,各位不要被这个「纸老虎」吓到了,我们可以手动打开一个网页试试看,有木有惊喜呢。
原来也是一个静态文件地址
具体地,我们看到这个数据文件对应的链接地址是:http://www.czce.com.cn/portal/DFSStaticFiles/Future/2017/20171026/FutureDataDaily.xls,对其进行拆解看:
http://www.czce.com.cn/portal/DFSStaticFiles/Future/:数据文件所在的根目录2017/20171026/FutureDataDaily.xls:具体的文件地址,通用格式为 YYYY/YYYYmmdd/FutureDataDaily.xls,也就是说,我们可以根据历史的交易日期来生成所以交易日的文件链接,然后呢,通过遍礼下载得到我们想要的数据即可。
不过,这里有一个小小的坑,就是郑商所在 2015-10-01 前后有变动过相对路径的根目录的名称,也就是说,这个地方需要我们用交易日期来判断。我们来看看这段代码是这样写的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
## 在 2015-10-01 之前
exchURL1 <- "http://www.czce.com.cn/portal/exchange/"
## 在 2015-10-01 之后
exchURL2 <- "http://www.czce.com.cn/portal/DFSStaticFiles/Future/"
tempDir <- paste0 ( dataPath , exchCalendar[i , calendarYear] )
if ( ! dir.exists ( tempDir )) dir.create ( tempDir )
tempYear <- exchCalendar[i , calendarYear]
tempTradingDay <- exchCalendar[i , days]
## 需要改变根目录地址
tempURL <- ifelse ( tempTradingDay < '20151001' ,
paste0 ( exchURL1 , tempYear , '/datadaily/' , tempTradingDay , '.txt' ),
paste0 ( exchURL2 , tempYear , '/' , tempTradingDay , '/FutureDataDaily.xls' ))
destFile <- paste0 ( dataPath , '/' , exchCalendar[i , calendarYear] ,
"/" , tempTradingDay ,
ifelse ( tempTradingDay < '20151001' , '.txt' , '.xls' ))
然后便可以开启并行模式下载数据了:
1
try ( download.file ( tempURL , destFile , mode = 'wb' ))
如果事情都是按照我们预期,作为强迫症的我,必然要求这个世界能够按照自然界最优雅的方式来运行。可以,世界太大,坏人太多,结局很不好。
以上介绍了使用静态网页链接地址来下载文件,可惜对于部分的交易日期,郑商所似乎把原始的数据文件弄丢了。这个不得了,我们得程序现在罢工了,无法再继续下载数据了。
不过所幸的是,我们还有另外一套网页爬虫的技术。
我们知道,任何的网页,后面其实都是一堆的 HTML 代码而已,无他。所以,即使我们无法找到(郑商所没有提供)数据文件的链接地址,我们还是可以通过爬虫抓取网页的数据。这个就需要用到 Selenium。
首先需要做的是,开启 selenium 驱动,通过命令行来模拟网页访问,读取网页内容。
1
java -jar selenium-server-standalone-3.5.1.jar
接下来,我们可以通过 RSelenium 提供的端口,把数据载入内容。这样,我们通过使用 Firefox 来模拟登陆网页,然后读取具体的信息,找到相应的数据节点,并正确的识别节点内容。
1
2
3
4
5
6
7
8
9
10
11
tempPage <- paste0 ( 'http://www.czce.com.cn/portal/exchange/jyxx/hq/hq' , tempTradingDay , '.html' )
remDr <- remoteDriver ( remoteServerAddr = 'localhost'
, port = 4444
, browserName = 'firefox' )
remDr $ getStatus ()
remDr $ open ( silent = TRUE )
remDr $ navigate ( tempPage )
tempTable <- remDr $ findElements ( using = 'tag' , value = 'table' ) [[3]]
tempHTML <- tempTable $ getElementAttribute ( 'outerHTML' ) [[1]]
现在,我们把整个网页的内容加载到 R 的工作空间,接下来便可以使用 rvest 来解析网页内容了:
1
2
3
4
5
6
7
8
9
10
11
webData <- tempHTML %>%
read_html ( encoding = 'GB18030' ) %>%
html_node ( 'table' ) %>%
html_table ( fill = TRUE , header = FALSE ) %>%
as.data.table () %>%
.[ -1 ] %>%
rbind ( data.table ( X1 = c ( '' )), ., fill = TRUE )
webData[1 , X1 := paste0 ( '郑州商品交易所每日行情表(' ,
as.Date ( as.character ( tempTradingDay ), format = '%Y%m%d' ),
')' ) ]
整理数据,并写入文件
1
2
3
4
5
6
7
8
cols <- colnames ( webData ) [2 : ncol ( webData ) ]
webData[ , ( cols ) := lapply ( .SD , function ( x ){
gsub ( ',' , '' , x )
}), .SDcols = cols]
print ( webData )
fwrite ( webData , destFile , col.names = FALSE )
最后是扫尾工作,记得把不用的内存空间释放出来,下面是在 Linux 操作系统的命令,Windows 的各位可以自行 Google 搜索(不要用百度!不要用百度!不要用百度!)
1
2
3
4
5
6
# remDr$quit()
try ({
system ( 'pkill -f firefox' )
system ( 'pkill -f geckodriver' )
system ( 'rm -rf /tmp/rust_mozprofile*' )
})
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
################################################################################
##! czce.R
## 这是主函数:
## 用于从 郑商所 网站爬虫期货交易的日行情数据
## daily
##
##
## 注意:
##
## Author: fl@hicloud-investment.com
## CreateDate: 2017-10-16
################################################################################
################################################################################
## STEP 0: 初始化,载入包,设定初始条件
################################################################################
rm ( list = ls ())
logMainScript <- c ( "czce.R" )
if ( class ( try ( setwd ( '/home/fl/myData/' ))) == 'try-error' ) {
setwd ( '/run/user/1000/gvfs/sftp:host=192.168.1.166,user=fl/home/fl/myData' )
}
suppressMessages ({
source ( './R/Rconfig/myInit.R' )
})
library ( RSelenium )
################################################################################
## STEP 1: 获取对应的交易日期
################################################################################
ChinaFuturesCalendar <- fread ( "./data/ChinaFuturesCalendar/ChinaFuturesCalendar.csv" ,
colClasses = list ( character = c ( "nights" , "days" ))) %>%
.[days < format ( Sys.Date (), '%Y%m%d' ) ]
exchCalendar <- ChinaFuturesCalendar[ , ":=" ( calendarYear = substr ( days , 1 , 4 ),
calendarYearMonth = substr ( days , 1 , 6 ),
calendarMonth = substr ( days , 5 , 6 ),
calendarDay = substr ( days , 7 , 8 )) ]
dataPath <- '/home/william/Documents/Exchange/CZCE/'
# dataPath <- "./data/Bar/Exchange/CZCE/"
##------------------------------------------------------------------------------
if ( Sys.info () [ 'sysname' ] == 'Windows' ){
Sys.setenv ( "R_ZIPCMD" = "D:/Program Files/Rtools/bin/zip.exe" ) ## path to zip.exe
}
##------------------------------------------------------------------------------
################################################################################
## CZCE: 郑商所
## 1.持仓排名
## 2.仓单日报
################################################################################
## 在 2015-10-01 之前
exchURL1 <- "http://www.czce.com.cn/portal/exchange/"
## 在 2015-10-01 之后
exchURL2 <- "http://www.czce.com.cn/portal/DFSStaticFiles/Future/"
## =============================================================================
czceData <- function ( i ) {
tempDir <- paste0 ( dataPath , exchCalendar[i , calendarYear] )
if ( ! dir.exists ( tempDir )) dir.create ( tempDir )
tempYear <- exchCalendar[i , calendarYear]
tempTradingDay <- exchCalendar[i , days]
tempURL <- ifelse ( tempTradingDay < '20151001' ,
paste0 ( exchURL1 , tempYear , '/datadaily/' , tempTradingDay , '.txt' ),
paste0 ( exchURL2 , tempYear , '/' , tempTradingDay , '/FutureDataDaily.xls' ))
destFile <- paste0 ( dataPath , '/' , exchCalendar[i , calendarYear] ,
"/" , tempTradingDay ,
ifelse ( tempTradingDay < '20151001' , '.txt' , '.xls' ))
tryNo <- 0
## ---------------------------------------------------------------------------
while ( ( ! file.exists ( destFile ) | file.size ( destFile ) < 1000 ) & ( tryNo < 20 )){
if ( class ( try ( download.file ( tempURL , destFile , mode = 'wb' ))) == 'try-error' ) {
tempPage <- paste0 ( 'http://www.czce.com.cn/portal/exchange/jyxx/hq/hq' , tempTradingDay , '.html' )
remDr <- remoteDriver ( remoteServerAddr = 'localhost'
, port = 4444
, browserName = 'firefox' )
remDr $ getStatus ()
remDr $ open ( silent = TRUE )
remDr $ navigate ( tempPage )
tempTable <- remDr $ findElements ( using = 'tag' , value = 'table' ) [[3]]
tempHTML <- tempTable $ getElementAttribute ( 'outerHTML' ) [[1]]
webData <- tempHTML %>%
read_html ( encoding = 'GB18030' ) %>%
html_node ( 'table' ) %>%
html_table ( fill = TRUE , header = FALSE ) %>%
as.data.table () %>%
.[ -1 ] %>%
rbind ( data.table ( X1 = c ( '' )), ., fill = TRUE )
webData[1 , X1 := paste0 ( '郑州商品交易所每日行情表(' ,
as.Date ( as.character ( tempTradingDay ), format = '%Y%m%d' ),
')' ) ]
cols <- colnames ( webData ) [2 : ncol ( webData ) ]
webData[ , ( cols ) := lapply ( .SD , function ( x ){
gsub ( ',' , '' , x )
}), .SDcols = cols]
print ( webData )
fwrite ( webData , destFile , col.names = FALSE )
# remDr$quit()
try ({
system ( 'pkill -f firefox' )
system ( 'pkill -f geckodriver' )
system ( 'rm -rf /tmp/rust_mozprofile*' )
})
}
tryNo <- tryNo + 1
}
## ---------------------------------------------------------------------------
}
################################################################################
## STEP 2: 开启并行计算模式,下载数据
################################################################################
# cl <- makeCluster(max(round(detectCores()*3/4),4), type='FORK')
# parSapply(cl, 1:nrow(ChinaFuturesCalendar), function(i){
# ## ---------------------------------------------------------------------------
# try(czceData(i))
# ## ---------------------------------------------------------------------------
# })
# stopCluster(cl)
## =============================================================================
sapply ( 1 : nrow ( ChinaFuturesCalendar ), function ( i ){
try ( czceData ( i ))
})
## =============================================================================
与日行情数据爬虫相类似,我们也一样可以对期货公司层面的成交持仓排名数据进行网络爬虫。这里需要做的,其实就是把日行情数据的网页地址换成持仓排名的网页地址,即
1
2
3
4
5
6
7
## 直接下载文件的链接
tempURL <- ifelse ( tempTradingDay < '20151001' ,
paste0 ( exchURL1 , tempYear , '/datatradeholding/' , tempTradingDay , '.txt' ),
paste0 ( exchURL2 , tempYear , '/' , tempTradingDay , '/FutureDataHolding.xls' ))
## 数据爬虫的网页地址
tempPage <- paste0 ( 'http://www.czce.com.cn/portal/exchange/jyxx/pm/pm' , tempTradingDay , '.html' )
好吧,剩下就就直接上干货喽。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
################################################################################
## czce.R
## 用于下载郑商所期货公司持仓排名数据
##
## Author: William Fang
## Date : 2017-08-21
################################################################################
################################################################################
## STEP 0: 初始化,载入包,设定初始条件
################################################################################
rm ( list = ls ())
logMainScript <- c ( "czce.R" )
# setwd('/home/fl/myData/')
if ( class ( try ( setwd ( '/home/fl/myData/' ))) == 'try-error' ) {
setwd ( '/run/user/1000/gvfs/sftp:host=192.168.1.166,user=fl/home/fl/myData' )
}
suppressMessages ({
source ( './R/Rconfig/myInit.R' )
})
library ( RSelenium )
Sys.setlocale ( "LC_ALL" , 'en_US.UTF-8' )
ChinaFuturesCalendar <- fread ( "./data/ChinaFuturesCalendar/ChinaFuturesCalendar.csv" ,
colClasses = list ( character = c ( "nights" , "days" ))) %>%
.[days < format ( Sys.Date (), '%Y%m%d' ) ]
exchCalendar <- ChinaFuturesCalendar[ , ":=" ( calendarYear = substr ( days , 1 , 4 ),
calendarYearMonth = substr ( days , 1 , 6 ),
calendarMonth = substr ( days , 5 , 6 ),
calendarDay = substr ( days , 7 , 8 )) ]
dataPath <- '/home/william/Documents/oiRank/CZCE/'
# dataPath <- "./data/Bar/Exchange/CZCE/"
##------------------------------------------------------------------------------
if ( Sys.info () [ 'sysname' ] == 'Windows' ){
Sys.setenv ( "R_ZIPCMD" = "D:/Program Files/Rtools/bin/zip.exe" ) ## path to zip.exe
}
##------------------------------------------------------------------------------
################################################################################
## CZCE: 郑商所
## 1.持仓排名
## 2.仓单日报
################################################################################
## 在 2015-10-01 之前
exchURL1 <- "http://www.czce.com.cn/portal/exchange/"
## 在 2015-10-01 之后
exchURL2 <- "http://www.czce.com.cn/portal/DFSStaticFiles/Future/"
## =============================================================================
czceData <- function ( i ) {
tempDir <- paste0 ( dataPath , exchCalendar[i , calendarYear] )
if ( ! dir.exists ( tempDir )) dir.create ( tempDir , recursive = TRUE )
tempYear <- exchCalendar[i , calendarYear]
tempTradingDay <- exchCalendar[i , days]
tempURL <- ifelse ( tempTradingDay < '20151001' ,
paste0 ( exchURL1 , tempYear , '/datatradeholding/' , tempTradingDay , '.txt' ),
paste0 ( exchURL2 , tempYear , '/' , tempTradingDay , '/FutureDataHolding.xls' ))
destFile <- paste0 ( dataPath , '/' , exchCalendar[i , calendarYear] ,
"/" , tempTradingDay ,
ifelse ( tempTradingDay < '20151001' , '.txt' , '.xls' ))
tryNo <- 0
## ---------------------------------------------------------------------------
while ( ( ! file.exists ( destFile ) | file.size ( destFile ) < 1000 ) & ( tryNo < 20 )){
if ( class ( try ( download.file ( tempURL , destFile , mode = 'wb' ))) == 'try-error' ) {
tempPage <- paste0 ( 'http://www.czce.com.cn/portal/exchange/jyxx/pm/pm' , tempTradingDay , '.html' )
webData <- tempPage %>%
read_html ( encoding = 'GB18030' ) %>%
html_nodes ( 'table' ) %>%
html_table ( fill = TRUE , header = FALSE ) %>%
.[ -1 ] %>%
.[[1]] %>%
as.data.table () %>%
rbind ( data.table ( X1 = c ( '' , '' )), ., fill = TRUE )
webData[1 , X1 := paste0 ( '郑州商品交易所持仓排行表(' ,
as.Date ( as.character ( tempTradingDay ), format = '%Y%m%d' ),
')' ) ]
cols <- colnames ( webData ) [2 : ncol ( webData ) ]
webData[ , ( cols ) := lapply ( .SD , function ( x ){
gsub ( ',' , '' , x )
}), .SDcols = cols]
# grep("名次", tempData$X1) %>% length()
webTitle <- tempPage %>%
read_html ( encoding = 'GB18030' ) %>%
html_nodes ( 'font' ) %>%
html_text () %>%
.[grep ( '品种|合约代码' , .)]
for ( j in 1 : length ( webTitle )) {
tempRow <- grep ( "名次" , webData $ X1 ) [j] - 1
webData[tempRow , X1 := webTitle[j]]
}
print ( webData )
fwrite ( webData , destFile , col.names = FALSE )
}
tryNo <- tryNo + 1
}
## ---------------------------------------------------------------------------
}
################################################################################
## STEP 2: 开启并行计算模式,下载数据
################################################################################
cl <- makeCluster ( max ( round ( detectCores () * 3 / 4 ), 4 ), type = 'FORK' )
parSapply ( cl , 1 : nrow ( ChinaFuturesCalendar ), function ( i ){
## ---------------------------------------------------------------------------
try ( czceData ( i ))
## ---------------------------------------------------------------------------
})
stopCluster ( cl )
# ## =============================================================================
# sapply(1:nrow(ChinaFuturesCalendar), function(i){
# try(czceData(i))
# })
# ## =============================================================================
 william 收录于 Data
william 收录于 Data

 支付宝
支付宝
 微信
微信